# A tibble: 2 × 8
Tratamiento n media mediana sd varianza min max
<fct> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
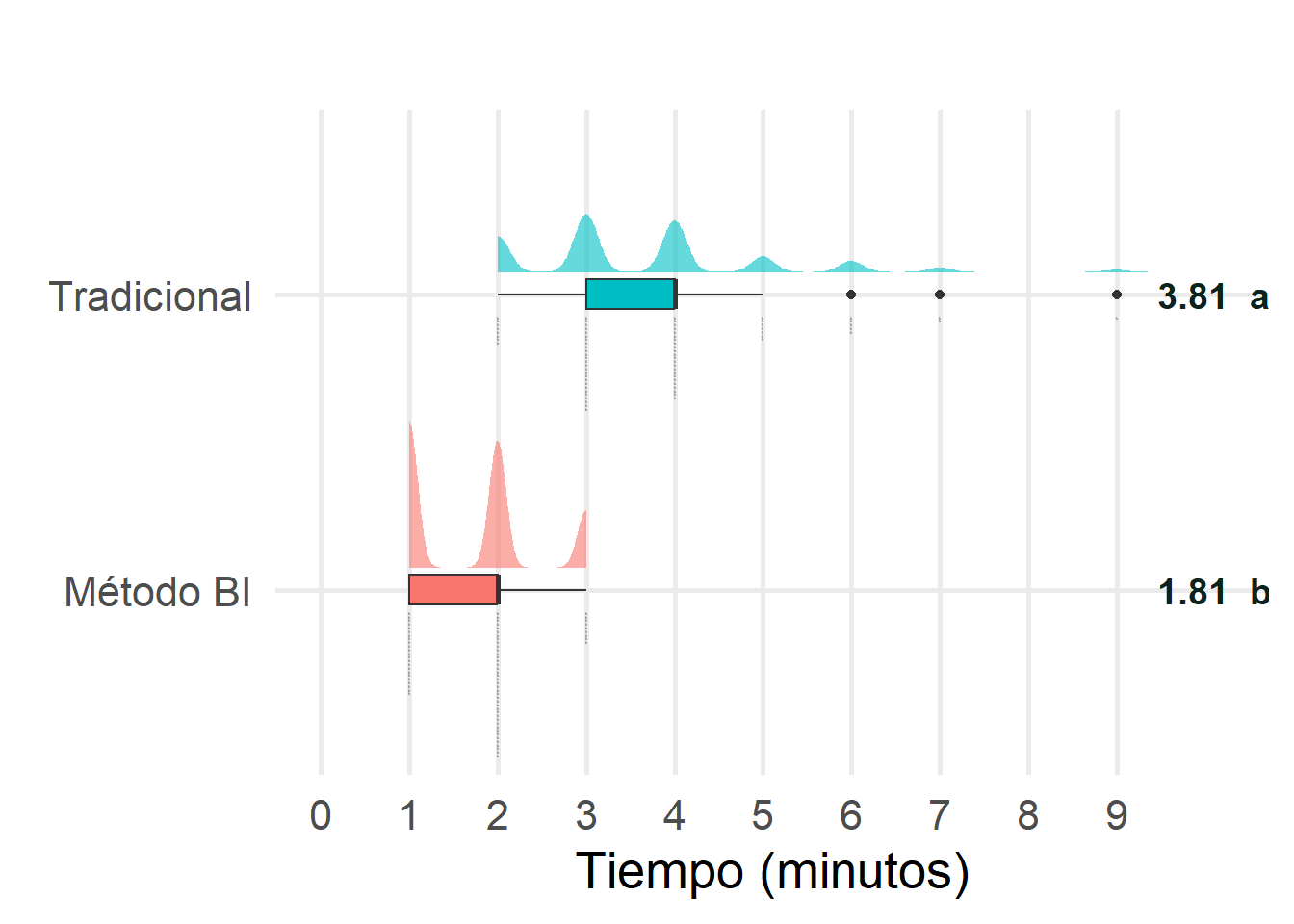
1 tiempo0dda 72 3.81 4 1.33 1.76 2 9
2 tiempo0ddaBI 72 1.81 2.00 0.642 0.412 1.00 3.00
J.0.1.1 Prueba de t
# Análisis estadístico# Realizar la prueba tt_test_result <-t.test(Tiempo ~ Tratamiento, data = data)# Mostrar los resultados de la prueba tprint(t_test_result)
Welch Two Sample t-test
data: Tiempo by Tratamiento
t = 11.502, df = 102.47, p-value < 2.2e-16
alternative hypothesis: true difference in means between group tiempo0dda and group tiempo0ddaBI is not equal to 0
95 percent confidence interval:
1.655131 2.344869
sample estimates:
mean in group tiempo0dda mean in group tiempo0ddaBI
3.805556 1.805556
J.0.1.2 Análisis de normalidad de los residuos utilizando Shapiro-Wilk
# Análisis de normalidad de los residuosmodel_subset <-lm(Tiempo ~ Tratamiento, data = data)shapiro_test_subset <-shapiro.test(residuals(model_subset))print(shapiro_test_subset)
Shapiro-Wilk normality test
data: residuals(model_subset)
W = 0.83996, p-value = 3.153e-11
J.0.2 Prueba no parametrica
# Realizar la prueba de Wilcoxonwilcox_test_result <-wilcox.test(Tiempo ~ Tratamiento, data = data, exact =FALSE)# Mostrar los resultados de la prueba de Wilcoxonprint(wilcox_test_result)
Wilcoxon rank sum test with continuity correction
data: Tiempo by Tratamiento
W = 5058, p-value < 2.2e-16
alternative hypothesis: true location shift is not equal to 0
J.0.3 Resumen gráfico
Código
library(ggdist)library(ggtext)# Comparar las medias para asignar los gruposif (t_test_result$p.value <0.05) {if (summary_stats$media[1] > summary_stats$media[2]) { summary_stats$groups <-c("a", "b") } else { summary_stats$groups <-c("b", "a") }} else { summary_stats$groups <-c("a", "a")}# Asignar nombres personalizados a los niveles del factor Tratamientodata$Tratamiento <-factor(data$Tratamiento, levels =c("tiempo0ddaBI", "tiempo0dda"), labels =c("Método BI", "Tradicional"))# Asegurarse de que los datos estén bien transformados para el gráficosummary_stats$Tratamiento <-factor(summary_stats$Tratamiento, levels =c("tiempo0ddaBI", "tiempo0dda"), labels =c("Método BI", "Tradicional"))graficoTiempoTtest <- data %>%ggplot(aes(x=Tiempo, y = Tratamiento, fill = Tratamiento)) +geom_boxplot(width =0.1) +geom_dots(side ='bottom',position =position_nudge(y =-0.075),height =0.55 ) +stat_slab(position =position_nudge(y =0.075),height =0.55,trim =FALSE,alpha =0.6 ) +labs(title="",y =element_blank(),x ="Tiempo (minutos)" ) +theme_minimal(base_size =20)+theme(text =element_text(family ="montserrat"),panel.grid.minor =element_blank(),legend.position ='none' )+geom_text(data = summary_stats, aes(x =9.2, y = Tratamiento, label =paste0(round(media, 2), " ", groups)), hjust =-0.2, size =5, color ="#0a231fff", fontface ="bold", hjust =1) +scale_x_continuous(breaks =seq(0, 9, by =1), # Divisiones cada 60 segundoslimits =c(0, 9.5) # Ajustar los límites para incluir el 0 y evitar que se corte el texto ) +coord_cartesian(xlim =c(0, 10.2))graficoTiempoTtest#ggsave("./Plots/graficoTiempoTtest.png", plot = graficoTiempoTtest, width=1920, height=1080, units = "px")# Calcular el porcentaje en relación con la media mayorsummary_stats <- summary_stats %>%mutate(porcentaje = (media /max(media)) *100)summary_stats
# A tibble: 2 × 10
Tratamiento n media mediana sd varianza min max groups porcentaje
<fct> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <chr> <dbl>
1 Tradicional 72 3.81 4 1.33 1.76 2 9 a 100
2 Método BI 72 1.81 2.00 0.642 0.412 1.00 3.00 b 47.4
Figura J.1
El costo de un empleado de campo para el ciclo 2023-2024 fue de $ 11,512.13 al mes, lo que equivale a aproximadamente $ 60.00 por hora. Para el muestreo por el método tradicional, se requieren dos personas, por lo que realizar el conteo de 72 subparcelas, como en el presente experimento, tendría un costo de $ 548.64 (3.81 min x 72 subparcelas x 2 personas). En cambio, para el método basado en imágenes se necesita solo una sola persona, lo que reduciría el costo a $ 130.32, es decir, 77% menos que el costo del método tradicional. En cuanto a la eficiencia de detección y conteo de maleza, aunque el el método basado en imágenes no tuvo diferencia significativa con el método tradicional, este alcanzó niveles de eficiencia de 1.16 para C. murale, 1.02 para A. palmeri, 1.11 para P. acutifolia y 1.03 para el complejo de maleza.
J.1 Eficiencia relativa de tratamientos herbicidas
# Leer los datos desde el archivo Exceldata_eficienciaRelativa <-read_excel("csv/eficienciaRelativa.xlsx")print(data_eficienciaRelativa)
# Redondear los valores a 2 decimalesdata_eficienciaRelativa$CostoRelativo <-round(data_eficienciaRelativa$CostoRelativo, 2)data_eficienciaRelativa$RendimientoRelativo <-round(data_eficienciaRelativa$RendimientoRelativo, 2)data_eficienciaRelativa$EficienciaRelativa <-round(data_eficienciaRelativa$EficienciaRelativa, 2)# Crear y mostrar la tablakable(data_eficienciaRelativa, format ="html", caption ="Subtítulo de la tabla") %>%kable_styling(bootstrap_options =c("striped", "hover", "condensed", "responsive")) %>%row_spec(0, bold =TRUE, color ="#ae8f5fff", background ="#0a231fff")