Dado que las distintas especies de maleza que se pueden encontrar en una parcela de cultivo no se distribuyen de manera aleatoria, e incluso existe una fuerte evidencia de agrupamiento (Riepma y Weng 1963), antes de someter los resultados a un análisis estadístico convencional, se se realizó el siguiente análisis para determinar la frecuencia de cada una de las especies y su distribución dentro de la parcela experimental.
F.0.1 Nivel de infestación de maleza
Este análisis proporciona un resumen visual de la frecuencia inicial de las distintas especies de maleza en las subparcelas y es fundamental para entender la distribución y densidad de las especies de malezas presentes.
F.0.1.1 Conteo previo
El siguiente gráfico muestra la frecuencia de aparición de las distintas especies de maleza encontradas en las 72 subparcelas en el conteo previo a la aplicación herbicida. De esta manera podemos determinar cuales especies de maleza se presentan con la suficiente frecuencia en nuestra parcela experimental como para ser sujetas a un análisis estadístico que nos permita realizar una comparación entre tratamientos. Se puede observar que solamente las especies de C. murale, A. palmeri, C. acutifolia y el complejo de maleza se presentaron con suficiente frecuencia para ser analizados (Figura F.1).
Mostrar el código.
# Leer los datos desde el archivo Exceldata <-read_excel("csv/datosMuestreo_final.xlsx")data_previo <-filter(data, data$conteo =="Previo")# Función para preparar los datos y crear el gráficocreate_species_plot <-function(species_name, data, total_parcelas) {# Filtrar los datos por especie species_data <- data %>%filter(especie == species_name)# Contar ocurrencias por parcela species_counts <- species_data %>%group_by(parcela) %>%summarise(Count =n()) %>%ungroup()# Crear una matriz vacía de 12x6 matrix_data <-matrix(0, nrow =12, ncol =6, dimnames =list(1:12, LETTERS[1:6]))# Rellenar la matriz con los datos contadosfor (i in1:nrow(species_counts)) { parcela <- species_counts$parcela[i] row_num <-as.numeric(substr(parcela, 2, 3)) # Corregir para extraer correctamente el número de fila (p.ej., 'A01' -> 1, 'A12' -> 12) col_num <-match(substr(parcela, 1, 1), LETTERS) # Extraer letra de columna de la parcela (p.ej., 'A01' -> A) matrix_data[row_num, col_num] <- species_counts$Count[i] }# Convertir la matriz en un dataframe largo para ggplot2 df_long <-as.data.frame(as.table(matrix_data))colnames(df_long) <-c("Row", "Column", "Count") df_long$Count <-as.numeric(as.character(df_long$Count))# Invertir el orden de las filas df_long$Row <-factor(df_long$Row, levels =1:12)# Calcular el total de ocurrencias y el porcentaje total_occurrences <-sum(df_long$Count) percentage <- (total_occurrences / total_parcelas) *100# Crear el gráfico p <-ggplot(df_long, aes(x = Column, y = Row)) +geom_tile(aes(fill = Count >0), color ="black") +# Ajustar la escala de colorscale_fill_manual(values =c("FALSE"="white", "TRUE"="green")) +# Solo pintar verde las celdas con valores > 0geom_text(aes(label =ifelse(Count >0, Count, "")), vjust =0.5, color ="black") +# Mostrar solo los valores > 0labs(title =paste0(species_name, " (", total_occurrences, "/", total_parcelas, ", ", round(percentage, 2), "%)"),x ="Columnas",y ="Filas" ) +theme_minimal() +theme(text =element_text(family ="montserrat"),axis.text =element_text(size =10, color ="#0a231fff"),axis.title =element_text(size =12, face ="bold", color ="#ae8f5fff"),plot.title =element_text(size =13, face ="bold", color ="#ae8f5fff"),legend.position ="none" ) +coord_fixed(ratio =7.5/8) # Ajustar la relación de aspectoreturn(p)}# Crear gráficos para las primeras 3 especies como ejemplospecies_list <-unique(data$especie)total_parcelas <-length(unique(data$parcela)) # Corregir el total de parcelas basado en el número de parcelas únicas# Graficar especies individuales directamenteInicialComplejo <-create_species_plot(species_list[4], data_previo, total_parcelas) # ComplejoInicialChualC <-create_species_plot(species_list[2], data_previo, total_parcelas) # Chual CInicialQuelite <-create_species_plot(species_list[1], data_previo, total_parcelas) # QueliteInicialTomatillo <-create_species_plot(species_list[3], data_previo, total_parcelas) # TomatilloInicialBorraja <-create_species_plot(species_list[5], data_previo, total_parcelas) # BorrajaInicialMalva <-create_species_plot(species_list[6], data_previo, total_parcelas) # MalvaInicialChualB <-create_species_plot(species_list[7], data_previo, total_parcelas) # Chual BInicialColaR <-create_species_plot(species_list[8], data_previo, total_parcelas) # Cola de RataInicialTrebol <-create_species_plot(species_list[9], data_previo, total_parcelas) # TrebolInicialVerdolaga <-create_species_plot(species_list[10], data_previo, total_parcelas) # VerdolagaInicialMalvaP <-create_species_plot(species_list[11], data_previo, total_parcelas) # Malva Plibrary(patchwork)InicialCombinacion <- InicialComplejo + InicialChualC + InicialQuelite + InicialTomatillo + InicialMalva + InicialChualB + InicialBorraja + InicialColaR + InicialVerdolaga + InicialTrebol + InicialMalvaP +plot_layout(ncol =4) #ggsave("./Plots/InicialCombinacion.png", plot = InicialCombinacion, width=10, height=14)
Figura F.1: Presencia de las distintas especies de maleza en el conteo previo a la aplicación de herbicida.
F.0.1.2 Desarrollo durante el experimento
Este análisis rastrea el progreso de la infestación de maleza a lo largo del tiempo en las parcelas experimentales. Incluye datos recolectados en diferentes momentos del experimento. Los cambios en la densidad y crecimiento de las malezas, representados en gráficos temporales, indican cómo los tratamientos afectan la infestación a lo largo del tiempo. Es útil para identificar tendencias y patrones de crecimiento.
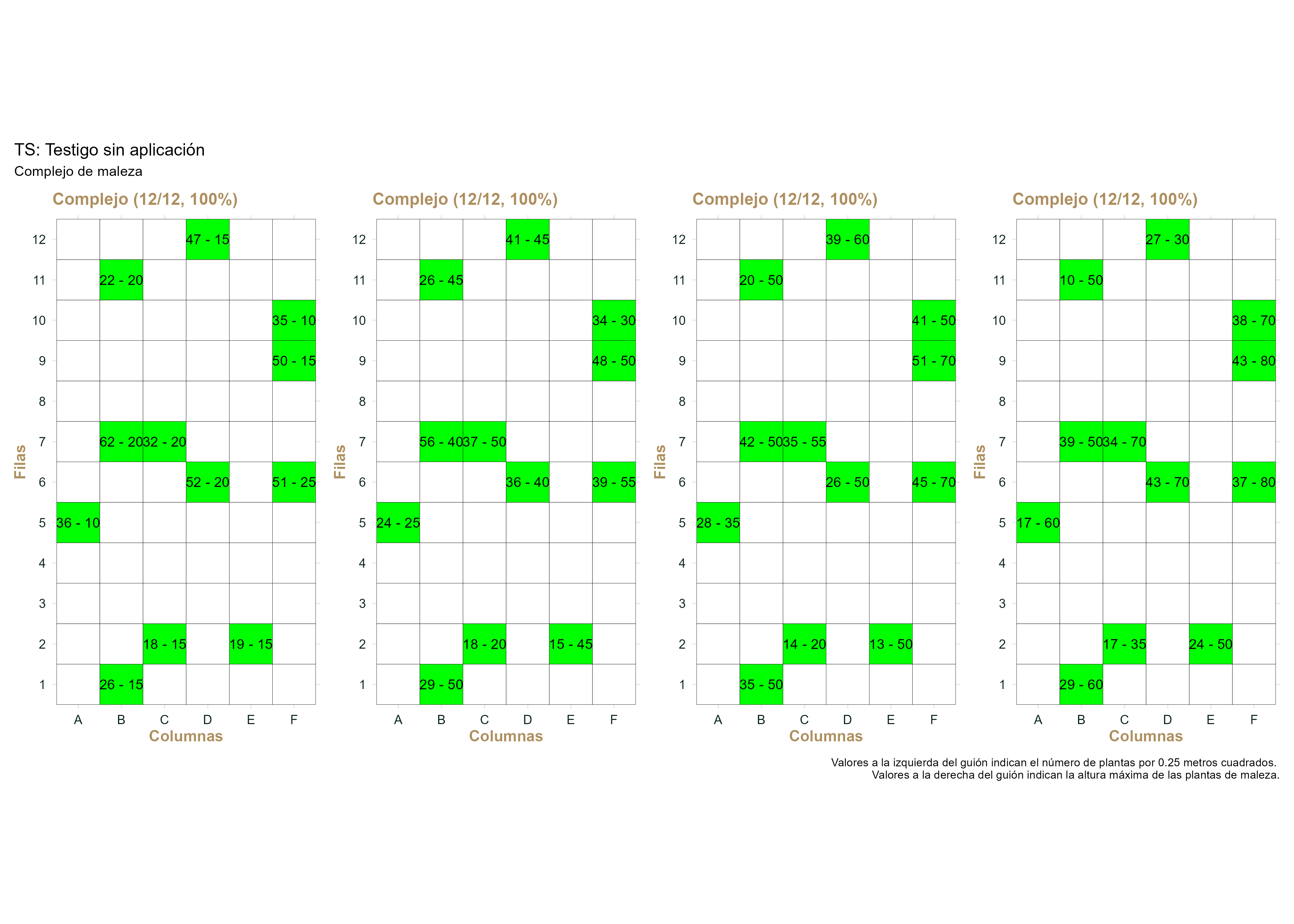
La Figura F.2 muestra el comportamiento del complejo de maleza en el testigo sin aplicación. Si observamos los valores del número de plantas (a la izquierda del guión en cada recuadro), podemos notar que la variación desde el conteo previo hasta los 28 dda se comportó de manera aleatoria, presentándose casos en los que el número de plantas de maleza fue mayor y en otros casos menor, con un promedio de 37 en el conteo previo y 30 en el conteo a los 28 dda, es decir, 19% menos. Por otra parte, el cambio en la altura máxima, durante el mismo periodo, presentó una tendencia mucho más coherente, aumentando desde 17 cm de promedio en el conteo previo, hasta 59 cm promedio en el conteo final; que representa un incremento del 253%.
Figura F.2: Desarrollo de la presencia del complejo de maleza durante el experimento en las parcelas del testigo sin aplicación.
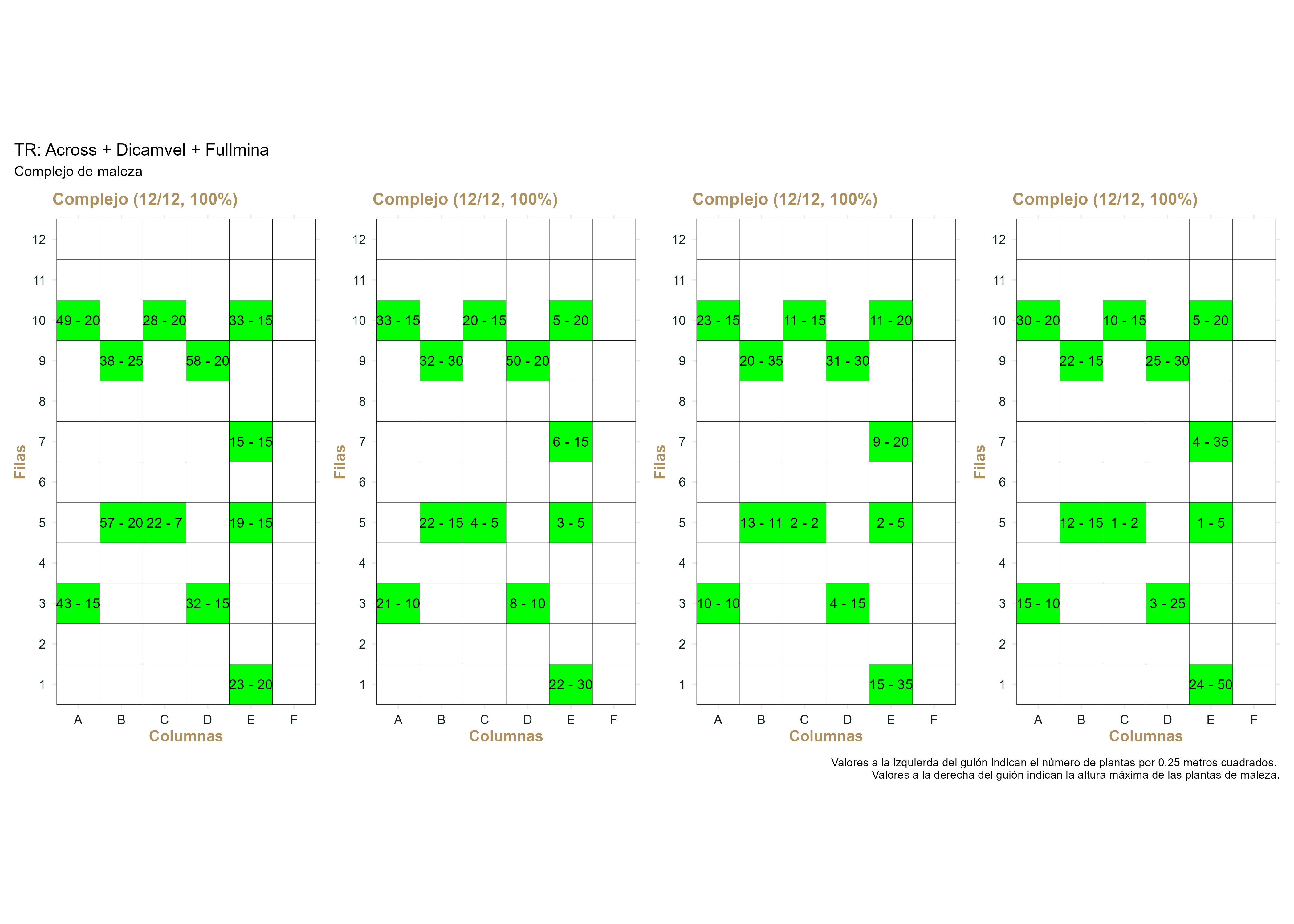
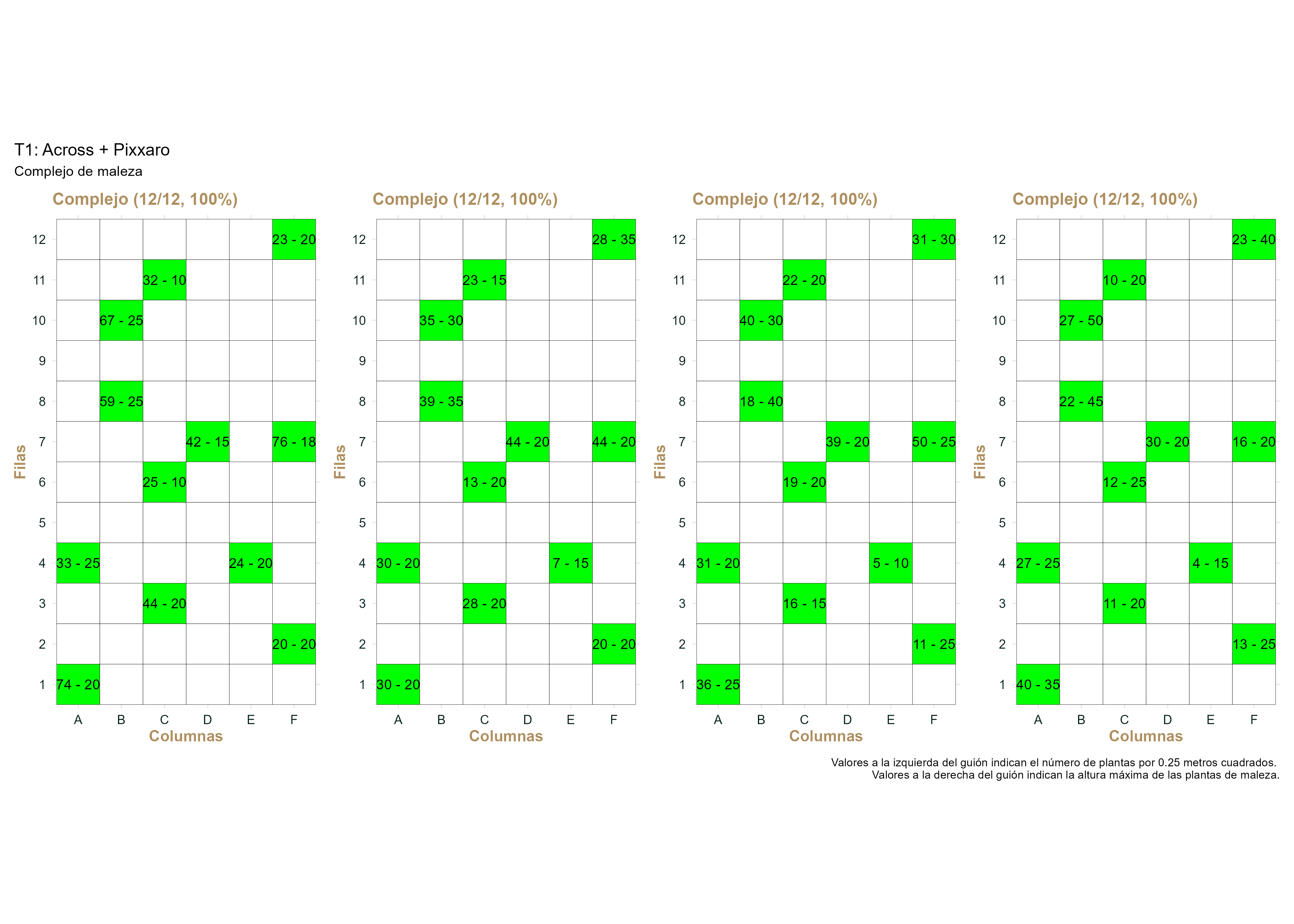
La Figura F.3 y Figura F.4 ejemplifican el comportamiento observado en las parcelas con aplicación herbicida. En este caso podemos observar que el número de plantas de maleza disminuyo moderadamente, y que la altura máxima se comportó de manera aleatoria. En las parcelas con aplicación del testigo regional, se contaron, en promedio, 35 plantas en el conteo previo y 13 plantas en el conteo a los 28 dda, una disminución del 62%. Si utilizamos la ecuación de Abbott (1925), y ajustamos de acuerdo al 19% de disminución en el número de plantas del testigo sin aplicación, esto representa solamente un 53% de control. Por otro lado, la altura máxima promedio de las plantas en el testigo regional incrementó 3 cm (16%).
Figura F.3: Desarrollo de la presencia del complejo de maleza durante el experimento en las parcelas del testigo regional.
Figura F.4: Desarrollo de la presencia del complejo de maleza durante el experimento en las parcelas del tratamiento 1.
De lo anterior, podemos suponer que, bajo las condiciones del experimento, el efecto de la aplicación de los tratamientos herbicidas, respecto al testigo sin aplicación, se expresó de manera más evidente en el cambio en altura máxima que en el cambio en el número de plantas.
F.0.2 Correlación de variables evaluadas y rendimiento
Para determinar si las variables evaluadas tuvieron un efecto sobre el rendimiento de trigo, y en que magnitud lo hicieron, se realizaron los siguientes análisis de correlación. El objetivo de este análisis es validar que las variables medidas son las correctas para explicar la variabilidad en el rendimiento. Esto es crucial, ya que demuestra que las variables de control evaluadas, el cambio en el número de plantas y la altura máxima, son suficientes para explicar las diferencias en el rendimiento observadas entre las subparcelas. Si estas variables explican una parte significativa de la variabilidad en el rendimiento, se puede proceder con confianza a los análisis comparativos entre tratamientos, sabiendo que se están utilizando las variables adecuadas para evaluar el impacto de los tratamientos sobre el rendimiento y el control de maleza.
Nota
En el contexto de análisis estadístico, es importante entender las diferencias entre el coeficiente de correlación de Pearson (r) y el coeficiente de determinación (R cuadrada).
Coeficiente de Correlación de Pearson (r):
El coeficiente de correlación de Pearson, denotado como r, es una medida de la fuerza y la dirección de la relación lineal entre dos variables cuantitativas.
r puede tomar valores entre -1 y 1. Los rangos y sus interpretaciones generales son los siguientes:
r=1: Correlación positiva perfecta. Las variables aumentan o disminuyen juntas de manera lineal perfecta.
0.7≤r<1: Correlación positiva fuerte.
0.4≤r<0.7: Correlación positiva moderada.
0.2≤r<0.4: Correlación positiva débil.
0≤r<0.2: Correlación positiva muy débil o inexistente.
r=0: No hay correlación lineal entre las variables.
−0.2≤r<0: Correlación negativa muy débil o inexistente.
−0.4≤r<−0.2: Correlación negativa débil.
−0.7≤r<−0.4: Correlación negativa moderada.
−1≤r<−0.7: Correlación negativa fuerte.
r=−1: Correlación negativa perfecta. Una variable aumenta mientras la otra disminuye de manera lineal perfecta.
Es importante recordar que el coeficiente de correlación de Pearson solo mide relaciones lineales y no implica causalidad entre las variables.
El coeficiente de correlación de Pearson no tiene unidades y no está limitado a la relación lineal; también puede capturar relaciones no lineales en algunos casos.
Coeficiente de Determinación (R cuadrada):
El coeficiente de determinación, denotado como R2, es una medida que indica cuánta variación en la variable de respuesta (variable dependiente) es explicada por el modelo de regresión lineal.
R2 se calcula como el cuadrado del coeficiente de correlación de Pearson (r), por lo que R2=r2.
R2 varía de 0 a 1, donde:
R2 = 0 indica que el modelo de regresión no explica ninguna variabilidad en la variable dependiente.
R2 = 1 indica que el modelo de regresión explica toda la variabilidad en la variable dependiente.
R2 se interpreta como la proporción de la variabilidad total de la variable dependiente que es explicada por el modelo de regresión lineal.
En resumen:
El coeficiente de correlación de Pearson (r) mide la fuerza y la dirección de la relación lineal entre dos variables.
El coeficiente de determinación (R cuadrada) es una medida de cuánta variabilidad en la variable dependiente es explicada por el modelo de regresión lineal.
F.0.2.1 Cambio en el número de plantas vs Rendimiento
Los datos del cambio en el número de plantas vs rendimiento (kg/ha) mostraron una correlación significativa (P = 0.011), con coeficiente de correlación de Pearson de -0.299, que se considera una correlación negativa débil; y un coeficiente de determinación de 0.089, lo cual indica que aproximadamente 9% de la variabilidad del rendimiento es explicada por el cambio en el número de plantas.
Mostrar el código.
correlacionRendimiento =read_excel(path ="csv/correlacionRendimiento.xlsx")correlacionRendimiento_ggControl <-ggplot(correlacionRendimiento, aes(cambioNoPlantas, Rendimiento)) +geom_point() +geom_smooth(method ='lm', formula = y ~ x, se =TRUE, fill ="blue", color ="blue", fullrange =TRUE, na.rm =TRUE, alpha =0.10, linetype ="dashed") +theme_classic() +labs(title =expression("Rendimiento vs"), subtitle ="Cambio en número de plantas") +xlab("Cambio en número de plantas") +ylab("Rendimiento") +theme(text =element_text(family ="montserrat"), axis.text =element_text(size =9), axis.title =element_text(size =9, face ="bold"), plot.title =element_text(size =9, face ="bold") ) +stat_regline_equation(aes(label =paste(..eq.label.., ..rr.label.., sep ="~~~~")), formula = y ~ x, label.x =-60, label.y =1500, output.type ="expression") +stat_cor(method ="pearson", label.x =-60, label.y =1000, p.accuracy =0.001, r.accuracy =0.001)print(correlacionRendimiento_ggControl)#ggsave("./Plots/correlacionRendimiento_ggControl.png", plot = correlacionRendimiento_ggControl, width=1920, height=1080, units = "px")
Figura F.5: Correlación entre el
F.0.2.2 Cambio en altura máxima vs rendimiento (kg/ha)
Los datos del cambio en la altura máxima vs rendimiento (kg/ha) mostraron una correlación significativa (P < 0.001), con coeficiente de correlación de Pearson de -0.424, que se considera una correlación negativa moderada; y un coeficiente de determinación de 0.18, lo cual indica que aproximadamente 18% de la variabilidad del rendimiento es explicada por el cambio en la altura máxima.
Mostrar el código.
correlacionRendimiento =read_excel(path ="csv/correlacionRendimiento.xlsx")correlacionRendimiento_ggCrecimiento <-ggplot(correlacionRendimiento, aes(cambioAltura, Rendimiento)) +geom_point() +geom_smooth(method ='lm', formula = y ~ x, se =TRUE, fill ="blue", color ="blue", fullrange =TRUE, na.rm =TRUE, alpha =0.10, linetype ="dashed") +theme_classic() +labs(title =expression("Rendimiento vs"), subtitle ="Crecimiento") +xlab("Crecimiento") +ylab("Rendimiento") +theme(text =element_text(family ="montserrat"), axis.text =element_text(size =9), axis.title =element_text(size =9, face ="bold"), plot.title =element_text(size =9, face ="bold") ) +stat_regline_equation(aes(label =paste(..eq.label.., ..rr.label.., sep ="~~~~")), formula = y ~ x, label.x =0, label.y =1500, output.type ="expression") +stat_cor(method ="pearson", label.x =0, label.y =1000, p.accuracy =0.001, r.accuracy =0.001)print(correlacionRendimiento_ggCrecimiento)#ggsave("./Plots/correlacionRendimiento_ggCrecimiento.png", plot = correlacionRendimiento_ggCrecimiento, width=1920, height=1080, units = "px")
Figura F.6: Correlación entre el
F.0.2.3 Predicción del modelo de regresión vs rendimiento real
La ecuación de regresión del modelo anterior nos permite calcular el rendimiento (y) conociendo el cambio en la altura máxima de las plantas de maleza (x). En la Tabla F.1 se muestra la comparación entre el rendimiento estimado por el modelo y el rendimiento promedio real de las 72 subparcelas y de cada uno de los tratamientos, en donde se puede apreciar un error promedio menor al 4%.
En este apartado, se llevó a cabo un análisis de covarianza (ANCOVA) para investigar si la combinación de dos variables, el cambio en el número de plantas y el cambio en la altura máxima, proporciona un modelo que explique mejor la variabilidad en el rendimiento (kg/ha) en comparación con el uso exclusivo de la altura máxima.
Los datos de la combinación de las dos variables vs rendimiento (kg/ha) mostraron una correlación significativa (P < 0.001), con coeficiente de correlación de Pearson de -0.458, que se considera una correlación negativa moderada; y un coeficiente de determinación de 0.21, lo cual indica que aproximadamente 21% de la variabilidad del rendimiento es explicada por el cambio en la altura máxima.
Los datos de la combinación de las dos variables vs rendimiento (kg/ha) mostraron una correlación significativa (P < 0.001), con coeficiente de correlación de Pearson de -0.458, que se considera una correlación negativa moderada; y un coeficiente de determinación de 0.21, lo cual indica que aproximadamente 21% de la variabilidad del rendimiento es explicada por la combinación del cambio en el número de plantas y el cambio en la altura máxima.
Mostrar el código.
# Ajustar el modelo de ANCOVAmodelo_ancova <-aov(Rendimiento ~ cambioNoPlantas + cambioAltura, data = correlacionRendimiento)# Resumen del modelosummary(modelo_ancova)
# Ajustar el modelo de ANCOVAmodelo_ancova2 <-lm(Rendimiento ~ cambioNoPlantas + cambioAltura, data = correlacionRendimiento)# Resumen del modeloresumen_modelo <-summary(modelo_ancova2)# Extraer R^2R2 <- resumen_modelo$r.squared# Calcular RR <-sqrt(R2)# Mostrar los valorescat("R^2:", R2, "\n")
R^2: 0.2104544
Mostrar el código.
cat("R:", R, "\n")
R: 0.4587531
Mostrar el código.
# Instalar y cargar la librería plotly#install.packages("htmlwidgets")#install.packages("crosstalk")#install.packages("promises")#install.packages("later")#install.packages("plotly")library(htmlwidgets)library(crosstalk)library(promises)library(later)library(plotly)# Ajustar el modelo de regresión lineal múltiplemodelo_ancova <-lm(Rendimiento ~ cambioNoPlantas + cambioAltura, data = correlacionRendimiento)# Crear una cuadrícula de puntos para el plano de regresióngrid <-expand.grid(cambioNoPlantas =seq(min(correlacionRendimiento$cambioNoPlantas), max(correlacionRendimiento$cambioNoPlantas), length.out =30),cambioAltura =seq(min(correlacionRendimiento$cambioAltura), max(correlacionRendimiento$cambioAltura), length.out =30))# Predecir los valores de Rendimiento para la cuadrículagrid$Rendimiento <-predict(modelo_ancova, newdata = grid)# Convertir las predicciones a una matriz con las dimensiones correctasz_matrix <-matrix(grid$Rendimiento, nrow =length(unique(grid$cambioNoPlantas)), ncol =length(unique(grid$cambioAltura)))# Crear el gráfico 3D con el plano de regresiónp4 <-plot_ly() %>%add_markers(data = correlacionRendimiento, x =~cambioNoPlantas, y =~cambioAltura, z =~Rendimiento, marker =list(size =3), name ="Datos") %>%add_surface(x =~unique(grid$cambioNoPlantas), y =~unique(grid$cambioAltura), z =~z_matrix,showscale =FALSE, opacity =0.5, name ="Plano de Regresión") %>%layout(title ="Gráfico 3D con Plano de Regresión",scene =list(xaxis =list(title ="Cambio en No. Plantas"),yaxis =list(title ="Cambio en Altura"),zaxis =list(title ="Rendimiento"),camera =list(eye =list(x =1.75, y =1.75, z =1.0) # Ajustar estos valores para cambiar el ángulo ) ))# Mostrar el gráfico 3Dp4
Figura F.7: Correlación entre el
Mostrar el código.
library(scatterplot3d)# Crear el gráfico 3Dscatter <-scatterplot3d(x = correlacionRendimiento$cambioNoPlantas, y = correlacionRendimiento$cambioAltura, z = correlacionRendimiento$Rendimiento,main ="Gráfico 3D con Plano de Regresión",xlab ="Cambio en No. Plantas", ylab ="Cambio en Altura (cm)", zlab ="Rendimiento (t/ha)",pch =16, highlight.3d =TRUE, angle =55, label.tick.marks = T, z.ticklabs =c("0", "1", "2", "3", "4", "5", "6", "7"))# Ajustar el modelo de regresión lineal múltiplemodelo_ancova <-lm(Rendimiento ~ cambioNoPlantas + cambioAltura, data = correlacionRendimiento)# Crear una cuadrícula de puntos para el plano de regresióngrid <-expand.grid(cambioNoPlantas =seq(min(correlacionRendimiento$cambioNoPlantas), max(correlacionRendimiento$cambioNoPlantas), length.out =30),cambioAltura =seq(min(correlacionRendimiento$cambioAltura), max(correlacionRendimiento$cambioAltura), length.out =30))# Predecir los valores de Rendimiento para la cuadrículagrid$Rendimiento <-predict(modelo_ancova, newdata = grid)# Verificar algunos valores predichos#head(grid)# Graficar el plano de regresiónscatter$plane3d(modelo_ancova, draw_polygon =TRUE, polygon_args =list(border ="blue"))
Figura F.8: Correlación entre el
F.0.3.1 Predicción del modelo de regresión vs rendimiento real
En la Tabla F.2 se muestra la comparación entre el rendimiento estimado por el modelo combinado y el rendimiento promedio real de las 72 subparcelas. El error promedio fue de 3.55%, sin mucha diferencia respecto al 3.69% obtenido al utilizar solamente la altura máxima. Esto sugiere que ambos modelos son muy similares en términos de su capacidad para explicar la variabilidad del rendimiento.
Dado que los modelos son comparables en su capacidad predictiva, y considerando que es un principio estadístico común optar por el modelo más sencillo cuando los modelos son similares en desempeño, se podría preferir el modelo que utiliza únicamente la altura máxima. Este enfoque no solo simplifica la interpretación y la aplicación práctica, sino que también reduce la posibilidad de sobreajuste.