# Análisis estadístico# Análisis de Varianza (ANOVA) considerando el efecto de Tratamiento y bloquemodel <-aov(Rendimiento ~ Tratamiento + bloque, data = data)anova_results <-Anova(model)# Mostrar los resultados del ANOVAprint(anova_results)
Shapiro-Wilk normality test
data: residuals(model)
W = 0.9449, p-value = 0.003365
I.0.2.3 Análisis de homogeneidad de varianzas utilizando la prueba de Levene
levene_test <- car::leveneTest(Rendimiento ~ Tratamiento, data = data)print(levene_test)
Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 5 1.1804 0.3283
66
I.0.2.4 Análisis de independencia de los residuos
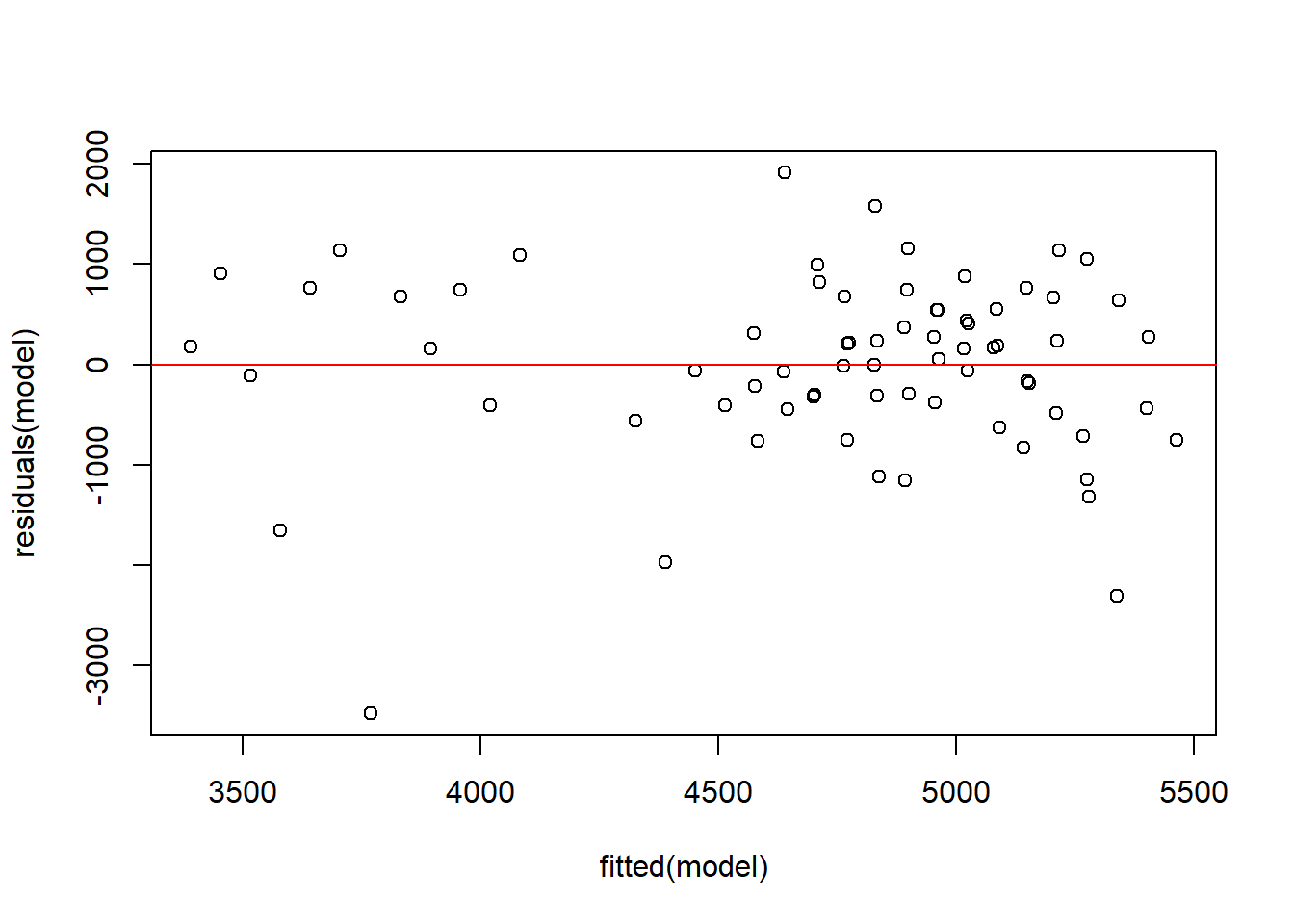
plot(residuals(model) ~fitted(model))abline(h =0, col ="red")
I.0.2.5 Comparaciones múltiples
# Comparaciones múltiples usando el test de Tukeytukey_results <-HSD.test(model, "Tratamiento")# Mostrar los resultados del test de Tukeyprint(tukey_results)
$statistics
MSerror Df Mean CV MSD
868877.9 65 4739.097 19.66907 1117.439
$parameters
test name.t ntr StudentizedRange alpha
Tukey Tratamiento 6 4.152742 0.05
$means
Rendimiento std r se Min Max Q25 Q50 Q75
T1 4929.167 727.0296 12 269.0845 3820 6050 4182.5 5025 5462.5
T2 4921.250 451.5032 12 269.0845 4315 5870 4565.0 4855 5235.0
T3 4671.667 1205.7577 12 269.0845 2420 6550 4022.5 4395 5555.0
T4 5058.333 788.2874 12 269.0845 3720 6350 4572.5 5005 5567.5
TR 5116.667 850.5756 12 269.0845 3030 6320 4725.0 5220 5640.0
TS 3737.500 1382.7517 12 269.0845 290 5170 3530.0 4205 4557.5
$comparison
NULL
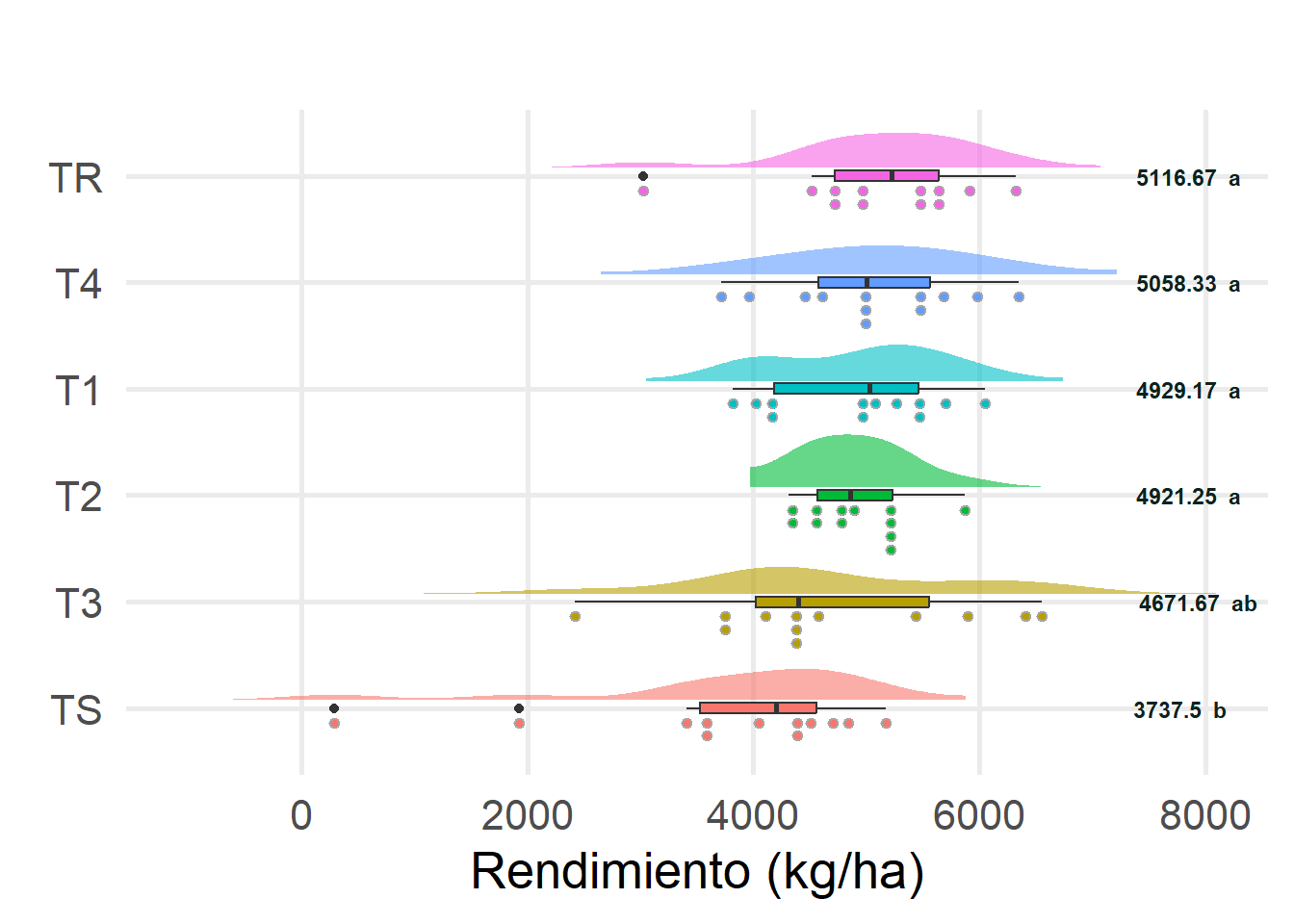
$groups
Rendimiento groups
TR 5116.667 a
T4 5058.333 a
T1 4929.167 a
T2 4921.250 a
T3 4671.667 ab
TS 3737.500 b
attr(,"class")
[1] "group"
I.0.3 Transformación de Box-Cox
# Cargar las librerías necesariaslibrary(MASS)library(car)
Warning: package 'car' was built under R version 4.2.3
Loading required package: carData
Attaching package: 'car'
The following object is masked from 'package:dplyr':
recode
The following object is masked from 'package:purrr':
some
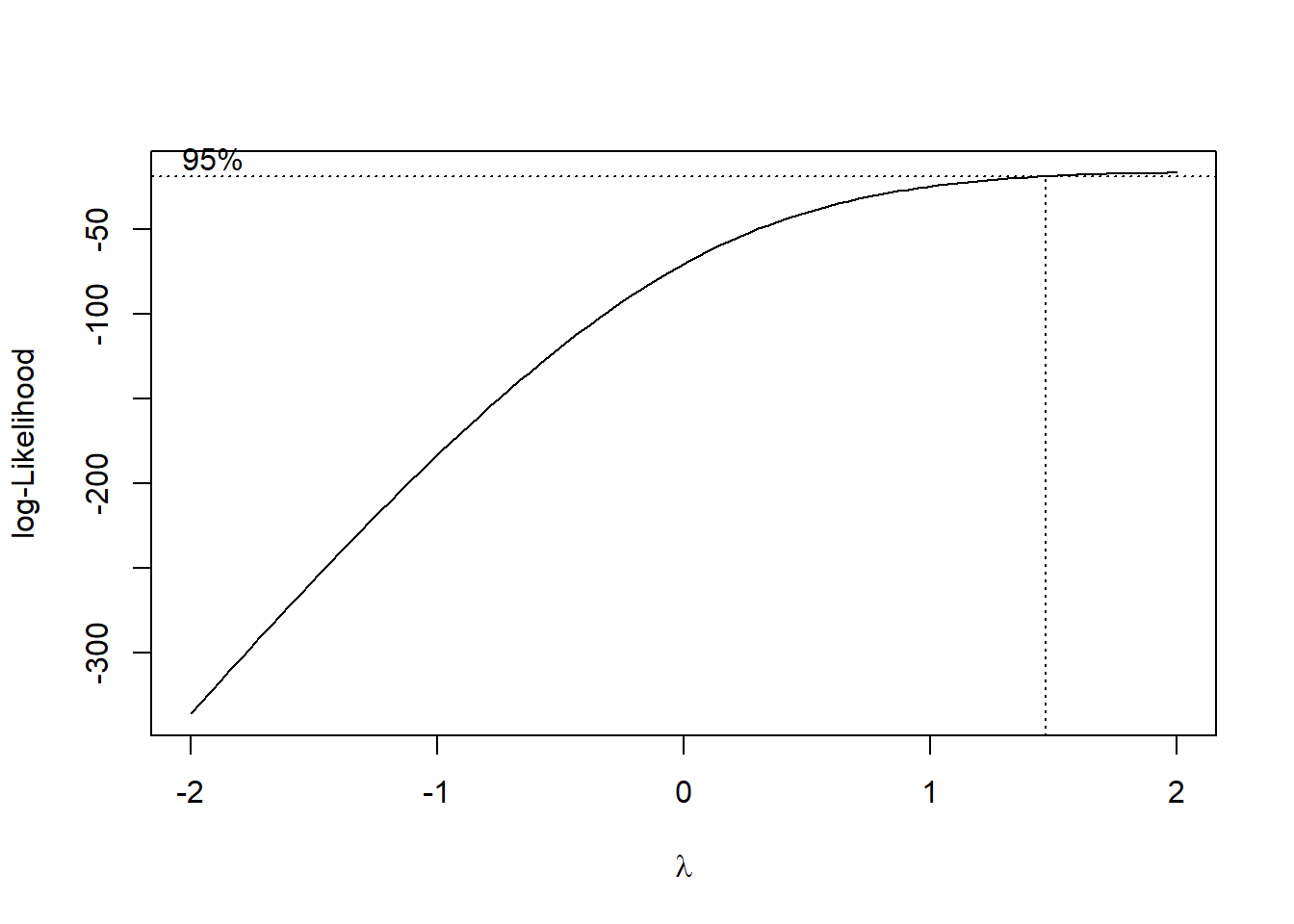
# Leer los datos desde el archivo Exceldata <-read_excel("csv/correlacionRendimiento.xlsx")# Convertir la columna 'Tratamiento' a factordata$Tratamiento <-as.factor(data$Tratamiento)data$bloque <-as.factor(data$bloque)# Aplicar la transformación de Box-Coxboxcox_results <-boxcox(Rendimiento ~ Tratamiento + bloque, data = data, lambda =seq(-2, 2, 0.1))
# Encontrar el mejor lambdabest_lambda <- boxcox_results$x[which.max(boxcox_results$y)]print(paste("Mejor lambda:", best_lambda))
[1] "Mejor lambda: 2"
# Transformar los datos usando el mejor lambdaif (best_lambda ==0) { data$transformed_Rendimiento <-log(data$Rendimiento)} else { data$transformed_Rendimiento <- (data$Rendimiento^best_lambda -1) / best_lambda}# Ajustar el modelo con los datos transformadosmodel_transformed <-aov(transformed_Rendimiento ~ Tratamiento + bloque, data = data)# Verificación de supuestos con los datos transformadosshapiro_test_transformed <-shapiro.test(residuals(model_transformed))levene_test_transformed <- car::leveneTest(transformed_Rendimiento ~ Tratamiento, data = data)# Resultados del modelo y verificación de supuestosanova_results_transformed <-Anova(model_transformed)print(anova_results_transformed)
Shapiro-Wilk normality test
data: residuals(model_transformed)
W = 0.98134, p-value = 0.3625
print(levene_test_transformed)
Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 5 0.993 0.4289
66
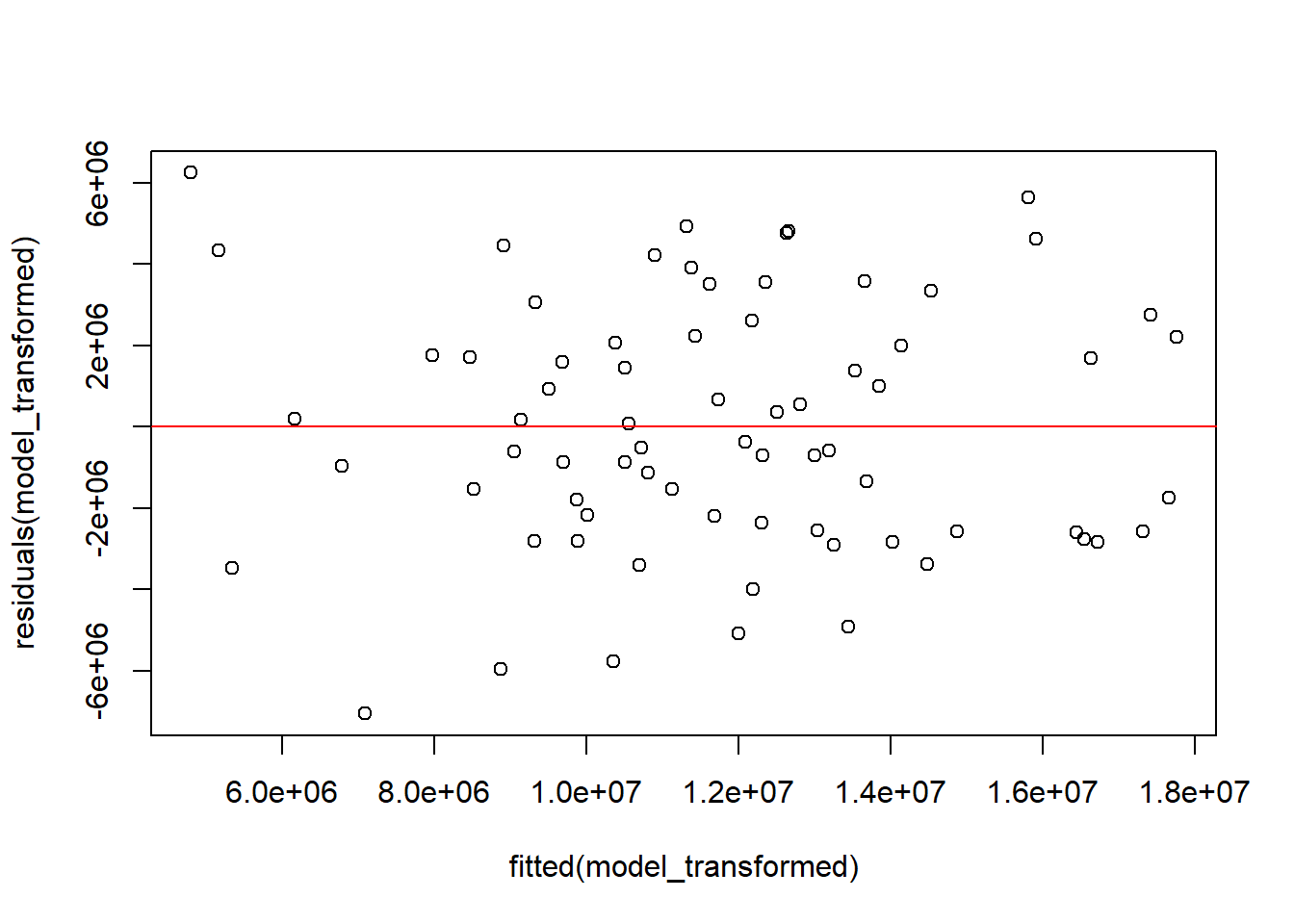
# Análisis de independencia de los residuos transformadosplot(residuals(model_transformed) ~fitted(model_transformed))abline(h =0, col ="red")
# Comparaciones múltiples usando el test de Tukey en datos transformadostukey_results_transformed <-HSD.test(model_transformed, "Tratamiento")print(tukey_results_transformed)
$statistics
MSerror Df Mean CV MSD
1.219784e+13 55 11755444 29.70998 4209793
$parameters
test name.t ntr StudentizedRange alpha
Tukey Tratamiento 6 4.175514 0.05
$means
transformed_Rendimiento std r se Min Max Q25
T1 12390604 3541710 12 1008209 7296199.5 18301250 8747112
T2 12202784 2274303 12 1008209 9309612.0 17228450 10419650
T3 11578583 5728882 12 1008209 2928199.5 21451250 8101737
T4 13078175 3960655 12 1008209 6919199.5 20161250 10455987
TR 13421733 4018910 12 1008209 4590449.5 19971200 11162850
TS 7860787 3956766 12 1008209 42049.5 13364450 6232850
Q50 Q75
T1 12626325 14919687
T2 11786125 13702650
T3 9658025 15448850
T4 12525125 15500637
TR 13653000 15904799
TS 8853025 10388787
$comparison
NULL
$groups
transformed_Rendimiento groups
TR 13421733 a
T4 13078175 a
T1 12390604 a
T2 12202784 a
T3 11578583 ab
TS 7860787 b
attr(,"class")
[1] "group"
I.0.4 Resumen gráfico
Código
library(ggdist)library(ggtext)# Leer los datos desde el archivo Exceldata <-read_excel("csv/correlacionRendimiento.xlsx")# Mostrar una vista previa de los datos#head(data)# Convertir la columna 'Tratamiento' a factordata$Tratamiento <-as.factor(data$Tratamiento)# Análisis descriptivosummary_stats <- data %>%group_by(Tratamiento) %>%summarise(n =n(),media =mean(Rendimiento, na.rm =TRUE),mediana =median(Rendimiento, na.rm =TRUE),sd =sd(Rendimiento, na.rm =TRUE),varianza =var(Rendimiento, na.rm =TRUE),min =min(Rendimiento, na.rm =TRUE),max =max(Rendimiento, na.rm =TRUE))# Preparar los datos del test de Tukeytukey_groups <- tukey_results_transformed$groupstukey_groups$Tratamiento <-rownames(tukey_groups)rownames(tukey_groups) <-NULL# Unir los resultados del test de Tukey con los summary_statssummary_stats <- summary_stats %>%left_join(tukey_groups, by ="Tratamiento")# Ordenar el eje Y de manera descendentedata$Tratamiento <-factor(data$Tratamiento, levels = summary_stats$Tratamiento[order(summary_stats$media)])graficoRendimientoTUKEY <- data %>%ggplot(aes(x=Rendimiento, y = Tratamiento, fill = Tratamiento)) +geom_boxplot(width =0.1) +geom_dots(side ='bottom',position =position_nudge(y =-0.075),height =0.55 ) +stat_slab(position =position_nudge(y =0.075),height =0.55,trim =FALSE,alpha =0.6 ) +labs(title="",y =element_blank(),x ="Rendimiento (kg/ha)" ) +theme_minimal(base_size =20)+theme(text =element_text(family ="montserrat"),panel.grid.minor =element_blank(),legend.position ='none' )+geom_text(data = summary_stats, aes(x =7200, y = Tratamiento, label =paste0(round(media, 2), " ", groups)), hjust =-0.2, size =3, color ="#0a231fff", fontface ="bold", hjust =1)graficoRendimientoTUKEY#ggsave("./Plots/graficoRendimientoTUKEY.png", plot = graficoRendimientoTUKEY, width=1920, height=1080, units = "px")
Figura I.1
I.0.5 Análisis no paramétrico
# Test de Kruskal-Walliskruskal_test <-kruskal.test(Rendimiento ~ Tratamiento, data = data)print(kruskal_test)
Kruskal-Wallis rank sum test
data: Rendimiento by Tratamiento
Kruskal-Wallis chi-squared = 13.388, df = 5, p-value = 0.02
I.0.5.1 Test de Dunn
library(FSA)
Warning: package 'FSA' was built under R version 4.2.3
Registered S3 methods overwritten by 'FSA':
method from
confint.boot car
hist.boot car
## FSA v0.9.5. See citation('FSA') if used in publication.
## Run fishR() for related website and fishR('IFAR') for related book.
Attaching package: 'FSA'
The following object is masked from 'package:car':
bootCase
dunn_test <-dunnTest(Rendimiento ~ Tratamiento , data = data, method ="bonferroni")print(dunn_test)
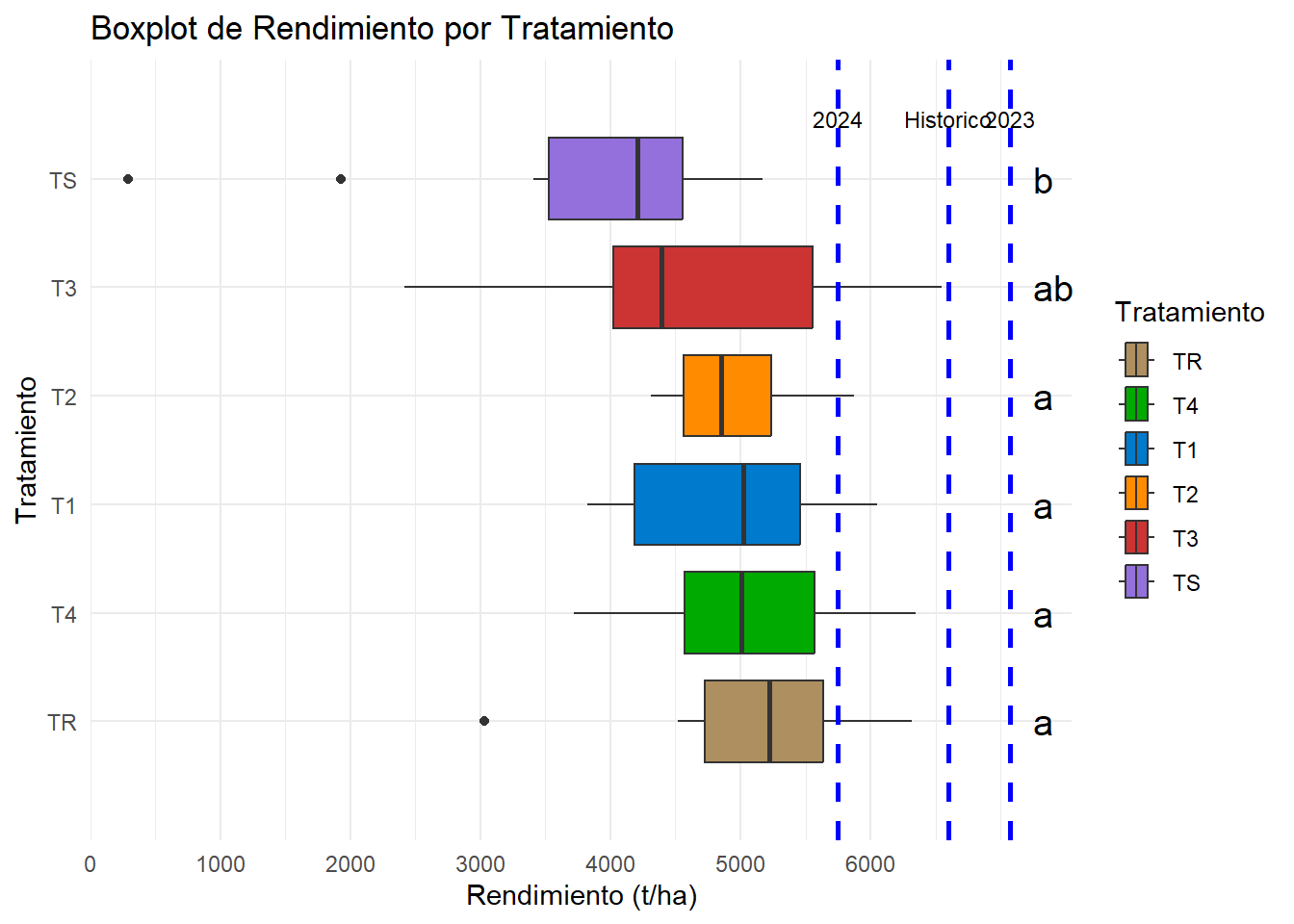
# Extraer los grupos de Tukeytukey_groups <-as.data.frame(tukey_results_transformed$groups)# Añadir la columna 'Tratamiento' a 'tukey_groups' para mapearlo en el gráficotukey_groups$Tratamiento <-rownames(tukey_groups)# Ordenar el eje Y por rendimiento medio (de mayor a menor)data$Tratamiento <-fct_reorder(data$Tratamiento, -tukey_groups$transformed_Rendimiento[match(data$Tratamiento, tukey_groups$Tratamiento)])# Parámetros para las líneas verticaleslineas <-data.frame(x =c(6600, 5750, 7070),label =c("Historico", "2024", "2023"))# Paleta de colores personalizadacolores <-c("TR"="#AE8F5F", "T4"="#00AA00", "T1"="#007ACC", "T2"="#FF8C00", "T3"="#CC3333", "TS"="#9370DB")# Visualización gráfica con las letras de Tukey# Boxplot de rendimientos por tratamiento con ejes invertidos y letras de Tukeyboxplot_tratamiento <-ggplot(data, aes(y = Tratamiento, x = Rendimiento, fill = Tratamiento)) +geom_boxplot() +theme_minimal() +labs(title ="Boxplot de Rendimiento por Tratamiento", x ="Rendimiento (t/ha)", y ="Tratamiento") +theme(legend.position ="right") +# Colocar la leyenda a la derechageom_text(data = tukey_groups, aes(x =max(data$Rendimiento) +700, y = Tratamiento, label = groups), hjust =0, color ="black", size =5, position =position_dodge(width =0.9))+# Colocar la leyenda a la derechascale_x_continuous(expand =c(0, 0), breaks =seq(0, max(data$Rendimiento), by =1000)) +coord_cartesian(xlim =c(0, max(data$Rendimiento) +1000), ylim =c(0.5, 6.5))+geom_vline(data = lineas, aes(xintercept = x), linetype ="dashed", color ="blue", size =1) +annotate("text", x = lineas$x, y =6.4, label = lineas$label, vjust =-0.5, color ="black", size =3)+scale_fill_manual(values = colores)# Mostrar el boxplot de tratamientos con ejes invertidos y letras de Tukeyprint(boxplot_tratamiento)
Figura I.2: RendimientoBoxplot.
I.0.7 Gráfico de barras para el promedio de rendimiento por tratamiento
Mostrar el código.
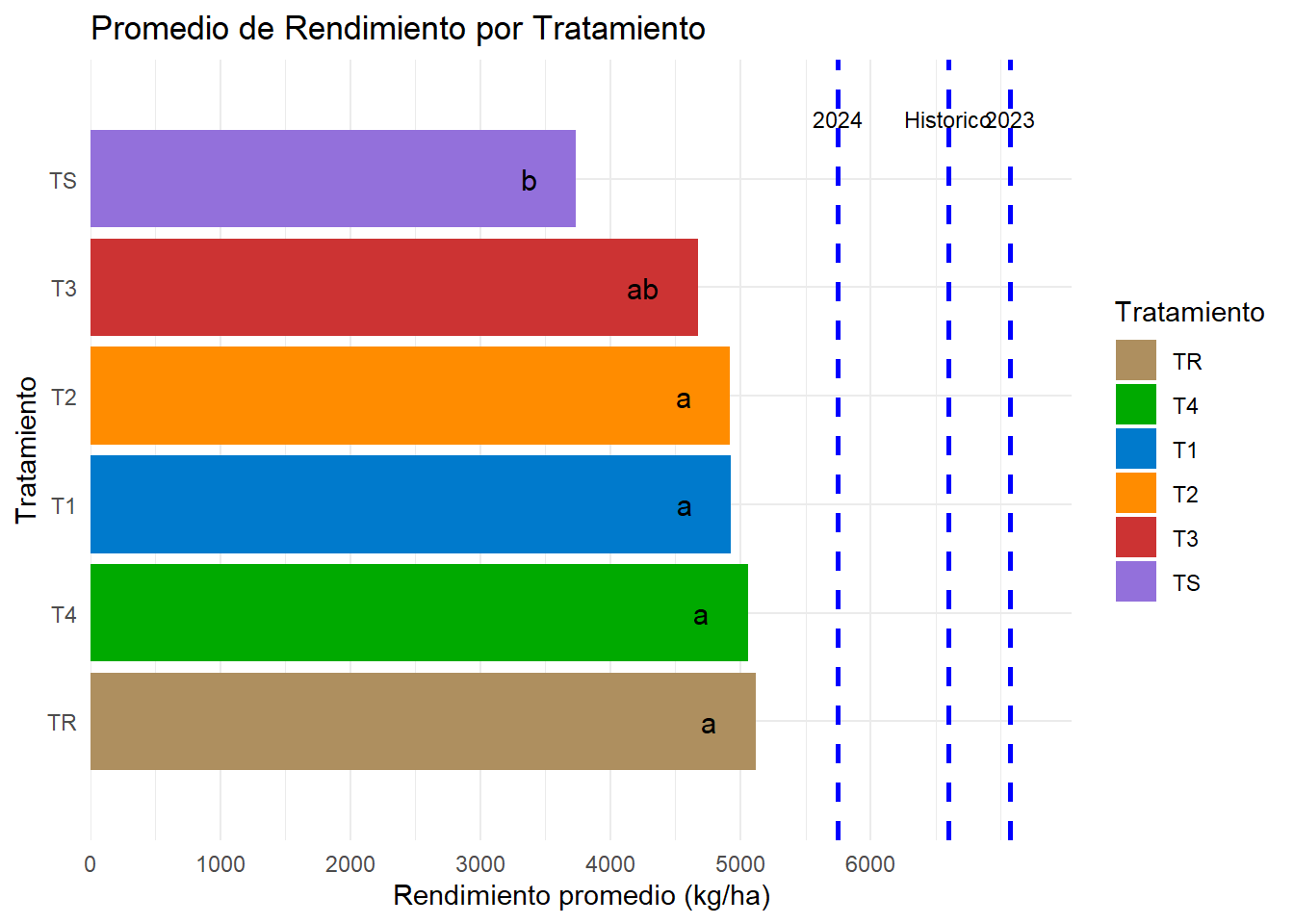
# Gráfico de barras para el promedio de rendimiento por tratamientobarplot_tratamiento <- data %>%group_by(Tratamiento) %>%summarise(media_rendimiento =mean(Rendimiento, na.rm =TRUE)) %>%mutate(Tratamiento =fct_reorder(Tratamiento, -media_rendimiento)) %>%# Reordenar factores de mayor a menorggplot(aes(x = media_rendimiento, y = Tratamiento, fill = Tratamiento)) +geom_bar(stat ="identity") +theme_minimal() +labs(title ="Promedio de Rendimiento por Tratamiento", x ="Rendimiento promedio (kg/ha)", y ="Tratamiento") +theme(legend.position ="right") +# Colocar la leyenda a la derechascale_x_continuous(expand =c(0, 0), breaks =seq(0, max(data$Rendimiento), by =1000)) +coord_cartesian(xlim =c(0, max(data$Rendimiento) +1000), ylim =c(0.5, 6.5)) +# Ajustar el límite del eje X y Ygeom_text(aes(x = media_rendimiento -300, y = Tratamiento, label = tukey_groups$groups[match(Tratamiento, tukey_groups$Tratamiento)]), hjust =1, color ="black", size =4) +# Colocar las letras Tukey dentro de las barras, cerca del eje Ygeom_vline(data = lineas, aes(xintercept = x), linetype ="dashed", color ="blue", size =1) +annotate("text", x = lineas$x, y =6.4, label = lineas$label, vjust =-0.5, color ="black", size =3)+scale_fill_manual(values = colores)# Mostrar el gráfico de barras de tratamientos con letras de Tukeyprint(barplot_tratamiento)
Figura I.3: RendimientoBarras.
I.0.8 Gráfico de barras para el promedio de rendimiento por tratamiento (Porcentaje respecto al testigo regional)
Mostrar el código.
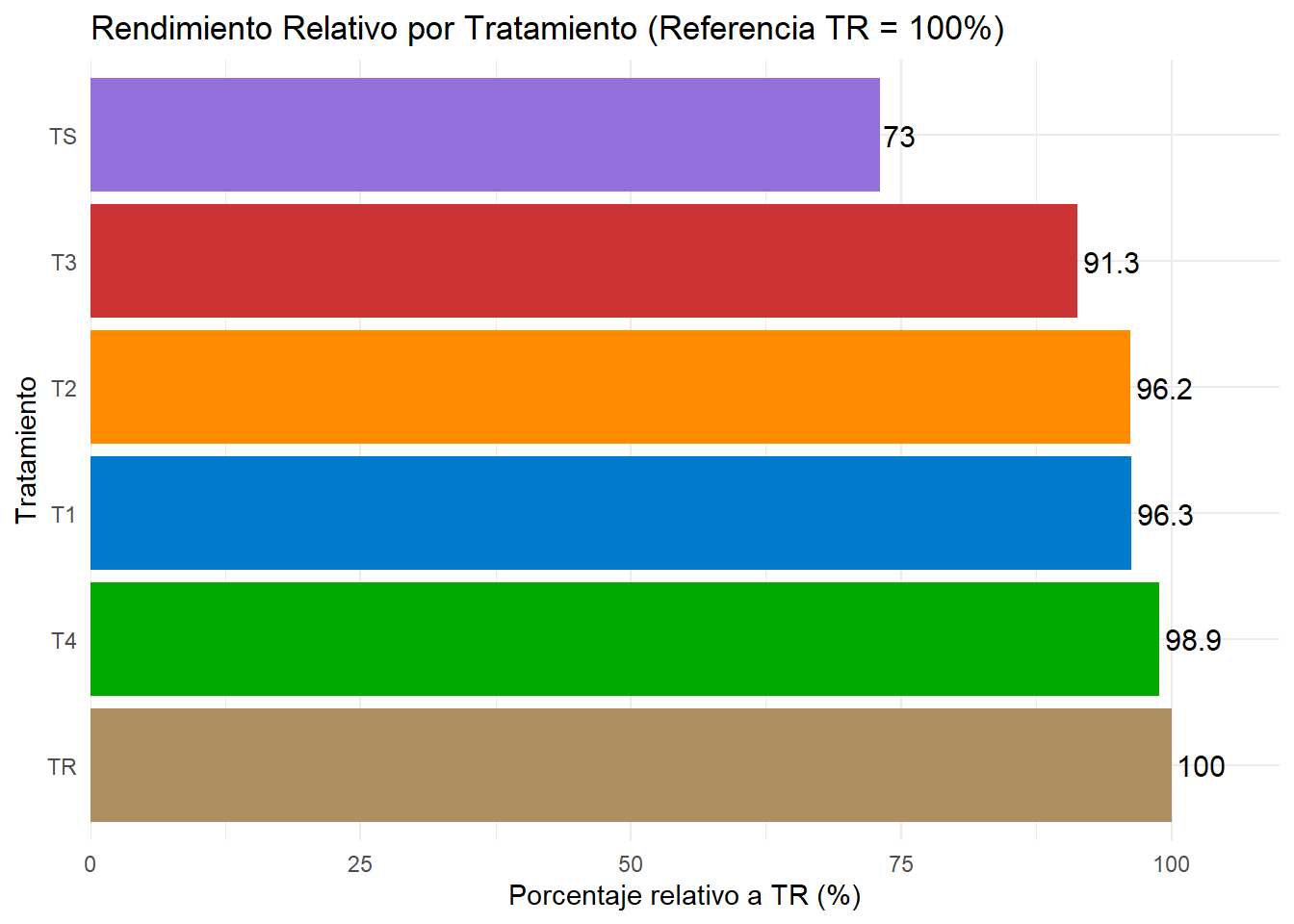
# Calcular el rendimiento promedio por tratamientopromedios <- data %>%group_by(Tratamiento) %>%summarise(media_rendimiento =mean(Rendimiento, na.rm =TRUE))# Obtener el rendimiento promedio del tratamiento TRrendimiento_tr <- promedios %>%filter(Tratamiento =="TR") %>%pull(media_rendimiento)# Calcular el porcentaje relativo al tratamiento TRpromedios <- promedios %>%mutate(porcentaje_relativo = (media_rendimiento / rendimiento_tr) *100)# Ordenar el eje Y por porcentaje relativo (de mayor a menor)promedios$Tratamiento <-fct_reorder(promedios$Tratamiento, -promedios$porcentaje_relativo)# Crear el gráfico de barrasbarplot_porcentaje <-ggplot(promedios, aes(x = porcentaje_relativo, y = Tratamiento, fill = Tratamiento)) +geom_bar(stat ="identity") +theme_minimal() +labs(title ="Rendimiento Relativo por Tratamiento (Referencia TR = 100%)", x ="Porcentaje relativo a TR (%)", y ="Tratamiento") +theme(legend.position ="none") +# Ocultar la leyenda ya que no es necesariageom_text(aes(label =round(porcentaje_relativo, 1)), hjust =-0.1, color ="black", size =4) +# Mostrar el porcentaje en las barrasscale_x_continuous(expand =c(0, 0), limits =c(0, max(promedios$porcentaje_relativo) *1.1)) +scale_fill_manual(values = colores)# Mostrar el gráfico de barrasprint(barplot_porcentaje)
Figura I.4: RendimientoBarrasPorcentaje.
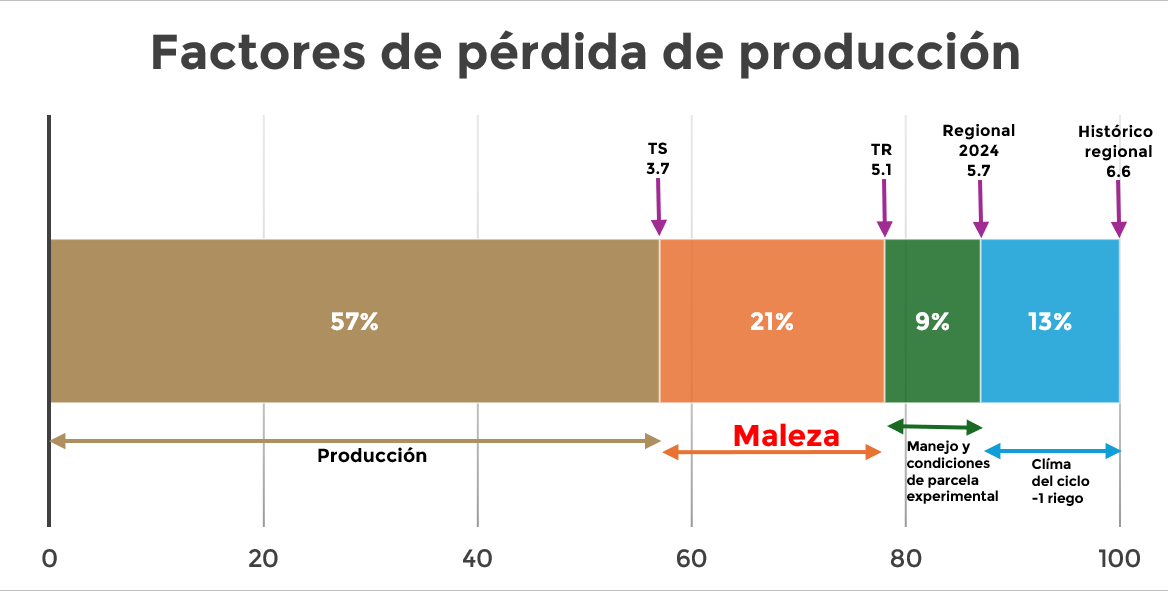
I.0.9 Comparación respecto a la producción histórica
Figura I.5: Pérdidas de producción debido a diversos factores