# Leer los datos desde el archivo Exceldata <-read_excel("csv/correlacionRendimiento.xlsx")# Mostrar una vista previa de los datos#head(data)# Convertir la columna 'Tratamiento' a factordata$Tratamiento <-as.factor(data$Tratamiento)# Análisis descriptivosummary_stats <- data %>%group_by(Tratamiento) %>%summarise(n =n(),media =mean(noPlantas0dda, na.rm =TRUE),mediana =median(noPlantas0dda, na.rm =TRUE),sd =sd(noPlantas0dda, na.rm =TRUE),varianza =var(noPlantas0dda, na.rm =TRUE),min =min(noPlantas0dda, na.rm =TRUE),max =max(noPlantas0dda, na.rm =TRUE))#print(summary_stats)# Crear y mostrar la tablakable(summary_stats, format ="html", caption ="Subtítulo de la tabla") %>%kable_styling(bootstrap_options =c("striped", "hover", "condensed", "responsive")) %>%row_spec(0, bold =TRUE, color ="#ae8f5fff", background ="#0a231fff")
# Análisis estadístico# Análisis de Varianza (ANOVA) considerando el efecto de Tratamiento y bloquemodel <-aov(noPlantas0dda ~ Tratamiento + bloque, data = data)anova_results <-Anova(model)# Mostrar los resultados del ANOVA#print(anova_results)# Crear y mostrar la tablakable(anova_results, format ="html", caption ="Anova Table (Type II tests) - Response: noPlantas0dda") %>%kable_styling(bootstrap_options =c("striped", "hover", "condensed", "responsive")) %>%row_spec(0, bold =TRUE, color ="#ae8f5fff", background ="#0a231fff")
Tabla H.2: Análisis de Varianza (ANOVA) considerando el efecto de Tratamiento y bloque…
Anova Table (Type II tests) - Response: noPlantas0dda
# Función para convertir un objeto htest a data.framehtest_to_df <-function(htest) {data.frame(Statistic = htest$statistic,P.Value = htest$p.value,Method = htest$method,Data.Name = htest$data.name )}# Uso de la función con la prueba Shapiro-Wilkshapiro_test <-shapiro.test(residuals(model))shapiro_test_df <-htest_to_df(shapiro_test)# Crear y mostrar la tablakable(shapiro_test_df, format ="html", caption ="Shapiro-Wilk normality test") %>%kable_styling(bootstrap_options =c("striped", "hover", "condensed", "responsive")) %>%row_spec(0, bold =TRUE, color ="#ae8f5fff", background ="#0a231fff")
Tabla H.3: Análisis de normalidad de los residuos utilizando Shapiro-Wilk…
# Función para combinar los medios y grupos en un solo data.frametukey_means_groups_to_df <-function(tukey_results) { means_df <-as.data.frame(tukey_results$means) groups_df <-as.data.frame(tukey_results$groups) combined_df <- groups_df %>%rownames_to_column("Treatment") %>%left_join(means_df %>%rownames_to_column("Treatment"), by ="Treatment") combined_df <- combined_df %>%arrange(desc(combined_df[[2]])) combined_df }# Comparaciones múltiples usando el test de Tukeytukey_results <-HSD.test(model, "Tratamiento")# Mostrar los resultados del test de Tukey#print(tukey_results)# Función para convertir las estadísticas y parámetros a data.framestats_df <-as.data.frame(tukey_results$statistics)params_df <-as.data.frame(tukey_results$parameters)# Convertir los resultados a data.framestukey_means_groups_df <-tukey_means_groups_to_df(tukey_results)# Crear y mostrar la tabla de estadísticaskable(stats_df, format ="html", caption ="Tukey Test Statistics") %>%kable_styling(bootstrap_options =c("striped", "hover", "condensed", "responsive")) %>%row_spec(0, bold =TRUE, color ="#ae8f5fff", background ="#0a231fff")
Tabla H.4: Comparaciones múltiples usando el test de Tukey…
# Crear y mostrar la tabla de parámetroskable(params_df, format ="html", caption ="Tukey Test Parameters") %>%kable_styling(bootstrap_options =c("striped", "hover", "condensed", "responsive")) %>%row_spec(0, bold =TRUE, color ="#ae8f5fff", background ="#0a231fff")
Tabla H.5: Comparaciones múltiples usando el test de Tukey…
# Crear y mostrar la tabla de medios y gruposkable(tukey_means_groups_df, format ="html", caption ="Tukey Test Means and Groups") %>%kable_styling(bootstrap_options =c("striped", "hover", "condensed", "responsive")) %>%row_spec(0, bold =TRUE, color ="#ae8f5fff", background ="#0a231fff")
Tabla H.6: Comparaciones múltiples usando el test de Tukey…
Tukey Test Means and Groups
Treatment
noPlantas0dda.x
groups
noPlantas0dda.y
std
r
se
Min
Max
Q25
Q50
Q75
T1
43.25000
a
43.25000
20.71067
12
4.674291
20
76
24.75
37.5
61.00
T3
40.08333
a
40.08333
16.24505
12
4.674291
12
65
31.25
39.5
52.75
TS
37.50000
a
37.50000
14.68766
12
4.674291
18
62
25.00
35.5
50.25
T2
35.58333
a
35.58333
14.02892
12
4.674291
16
59
28.50
32.5
46.75
TR
34.75000
a
34.75000
14.49843
12
4.674291
15
58
22.75
32.5
44.50
T4
33.75000
a
33.75000
15.30968
12
4.674291
10
61
23.50
35.0
40.25
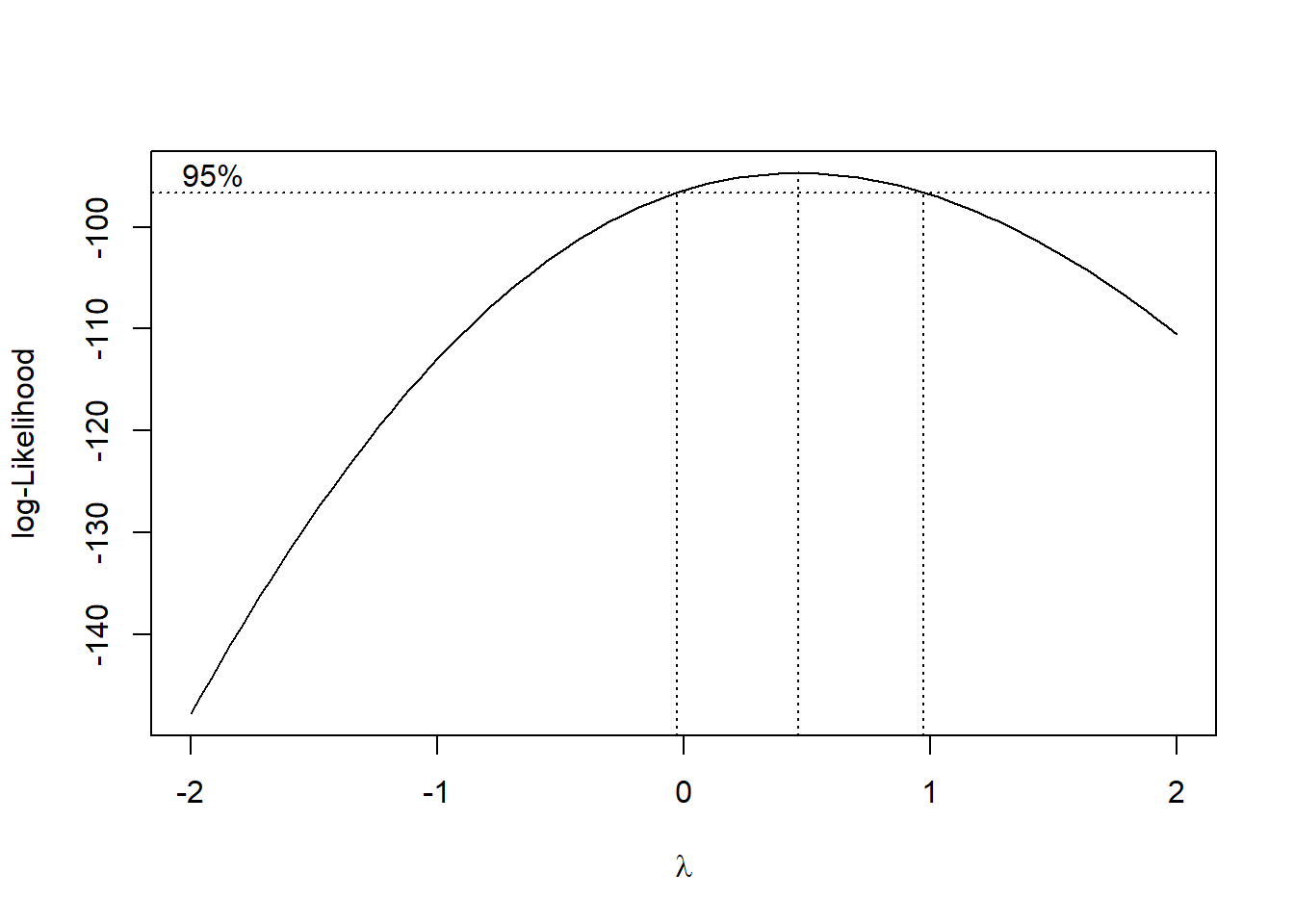
H.1.2 Transformación de Box-Cox
Código
# Cargar las librerías necesariaslibrary(MASS)library(car)# Leer los datos desde el archivo Exceldata <-read_excel("csv/correlacionRendimiento.xlsx")# Convertir la columna 'Tratamiento' a factordata$Tratamiento <-as.factor(data$Tratamiento)# Aplicar la transformación de Box-Coxboxcox_results <-boxcox(noPlantas0dda ~ Tratamiento + bloque, data = data, lambda =seq(-2, 2, 0.1))# Encontrar el mejor lambdabest_lambda <- boxcox_results$x[which.max(boxcox_results$y)]#print(paste("Mejor lambda:", best_lambda))# Transformar los datos usando el mejor lambdaif (best_lambda ==0) { data$transformed_noPlantas0dda <-log(data$noPlantas0dda)} else { data$transformed_noPlantas0dda <- (data$noPlantas0dda^best_lambda -1) / best_lambda}
Figura H.1: Gráfico de…
Código
# Ajustar el modelo con los datos transformadosmodel_transformed <-aov(transformed_noPlantas0dda ~ Tratamiento + bloque, data = data)# Verificación de supuestos con los datos transformadosshapiro_test_transformed <-shapiro.test(residuals(model_transformed))levene_test_transformed <- car::leveneTest(transformed_noPlantas0dda ~ Tratamiento, data = data)# Resultados del modelo y verificación de supuestosanova_results_transformed <-Anova(model_transformed)#print(anova_results_transformed)# Crear y mostrar la tablakable(anova_results_transformed, format ="html", caption ="Anova Table (Type II tests) - Response: noPlantas0dda") %>%kable_styling(bootstrap_options =c("striped", "hover", "condensed", "responsive")) %>%row_spec(0, bold =TRUE, color ="#ae8f5fff", background ="#0a231fff")
Tabla H.7: Comparaciones múltiples usando el test de Tukey…
Anova Table (Type II tests) - Response: noPlantas0dda
Sum Sq
Df
F value
Pr(>F)
Tratamiento
14.5132790
5
0.5126642
0.7657074
bloque
0.0017188
1
0.0003036
0.9861524
Residuals
368.0237973
65
NA
NA
Código
#print(shapiro_test_transformed)shapiro_test_df <-htest_to_df(shapiro_test_transformed)# Crear y mostrar la tablakable(shapiro_test_df, format ="html", caption ="Shapiro-Wilk normality test") %>%kable_styling(bootstrap_options =c("striped", "hover", "condensed", "responsive")) %>%row_spec(0, bold =TRUE, color ="#ae8f5fff", background ="#0a231fff")
Tabla H.8: Comparaciones múltiples usando el test de Tukey…
Shapiro-Wilk normality test
Statistic
P.Value
Method
Data.Name
W
0.9708748
0.0932019
Shapiro-Wilk normality test
residuals(model_transformed)
Código
print(levene_test_transformed)
Tabla H.9: Comparaciones múltiples usando el test de Tukey…
Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 5 0.3396 0.8871
66
Código
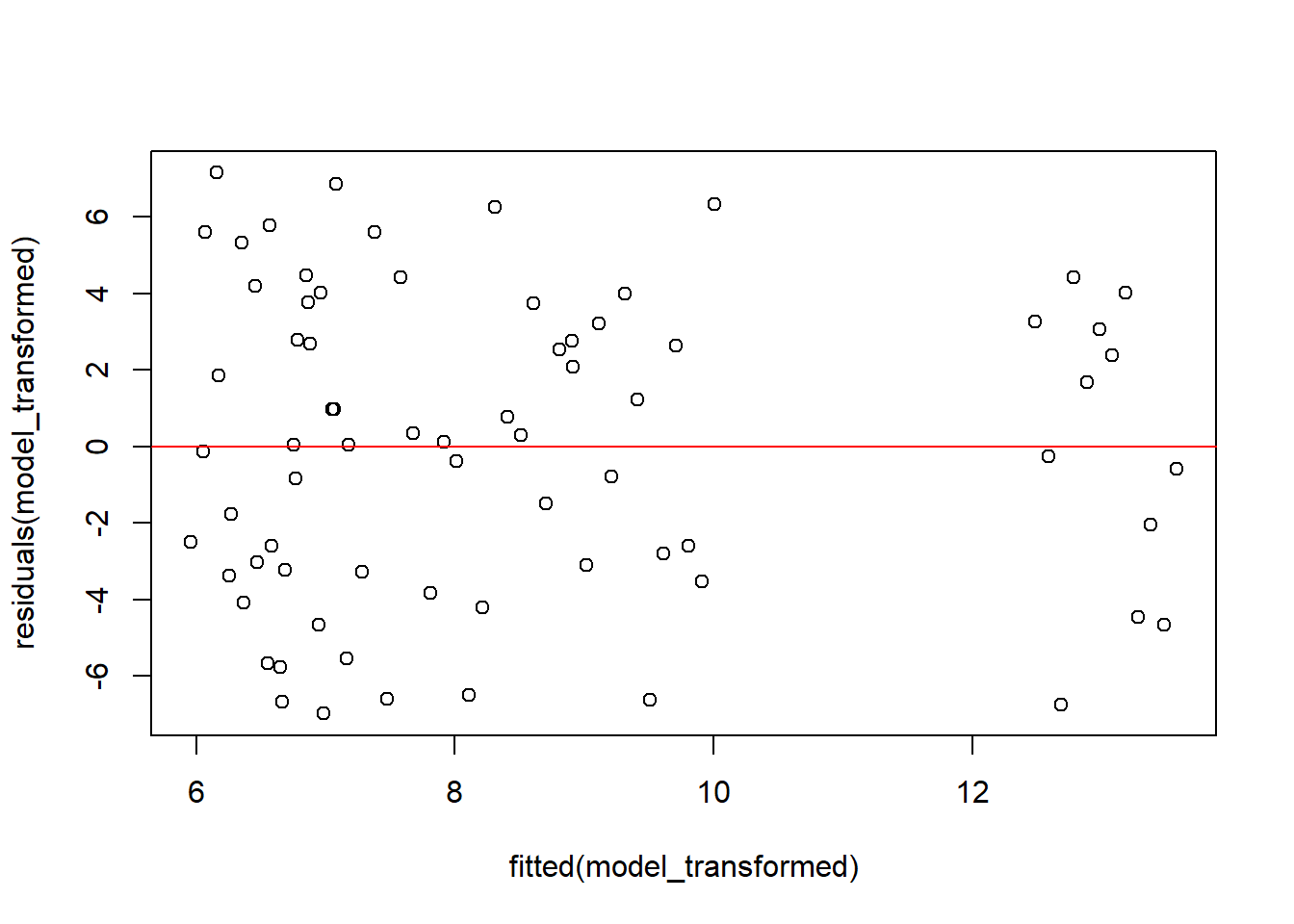
# Análisis de independencia de los residuos transformadosplot(residuals(model_transformed) ~fitted(model_transformed))abline(h =0, col ="red")
Tabla H.10: Comparaciones múltiples usando el test de Tukey…
Código
# Comparaciones múltiples usando el test de Tukey en datos transformadostukey_results_transformed <-HSD.test(model_transformed, "Tratamiento")#print(tukey_results_transformed)# Función para convertir las estadísticas y parámetros a data.framestats_df <-as.data.frame(tukey_results_transformed$statistics)params_df <-as.data.frame(tukey_results_transformed$parameters)# Convertir los resultados a data.framestukey_means_groups_df <-tukey_means_groups_to_df(tukey_results_transformed)# Crear y mostrar la tabla de estadísticaskable(stats_df, format ="html", caption ="Tukey Test Statistics") %>%kable_styling(bootstrap_options =c("striped", "hover", "condensed", "responsive")) %>%row_spec(0, bold =TRUE, color ="#ae8f5fff", background ="#0a231fff")
Tabla H.11: Comparaciones múltiples usando el test de Tukey…
Tukey Test Statistics
MSerror
Df
Mean
CV
MSD
5.661905
65
9.173888
25.93748
2.852499
Código
# Crear y mostrar la tabla de parámetroskable(params_df, format ="html", caption ="Tukey Test Parameters") %>%kable_styling(bootstrap_options =c("striped", "hover", "condensed", "responsive")) %>%row_spec(0, bold =TRUE, color ="#ae8f5fff", background ="#0a231fff")
Tabla H.12: Comparaciones múltiples usando el test de Tukey…
Tukey Test Parameters
test
name.t
ntr
StudentizedRange
alpha
Tukey
Tratamiento
6
4.152742
0.05
Código
# Crear y mostrar la tabla de medios y gruposkable(tukey_means_groups_df, format ="html", caption ="Tukey Test Means and Groups") %>%kable_styling(bootstrap_options =c("striped", "hover", "condensed", "responsive")) %>%row_spec(0, bold =TRUE, color ="#ae8f5fff", background ="#0a231fff")
Tabla H.13: Comparaciones múltiples usando el test de Tukey…
Tukey Test Means and Groups
Treatment
transformed_noPlantas0dda.x
groups
transformed_noPlantas0dda.y
std
r
se
Min
Max
Q25
Q50
Q75
T1
9.916343
a
9.916343
2.723103
12
0.6868955
6.505403
13.94652
7.406121
9.421287
12.377497
T3
9.544688
a
9.544688
2.432420
12
0.6868955
4.676166
12.81849
8.498041
9.713849
11.433139
TS
9.226914
a
9.226914
2.166952
12
0.6868955
6.091775
12.49338
7.445240
9.150333
11.130950
T2
8.949846
a
8.949846
2.130288
12
0.6868955
5.652728
12.15973
8.042877
8.695980
10.691653
TR
8.811846
a
8.811846
2.184570
12
0.6868955
5.422152
12.04651
7.039068
8.695980
10.396671
T4
8.593692
a
8.593692
2.473613
12
0.6868955
4.121527
12.38314
7.163799
9.075221
9.816479
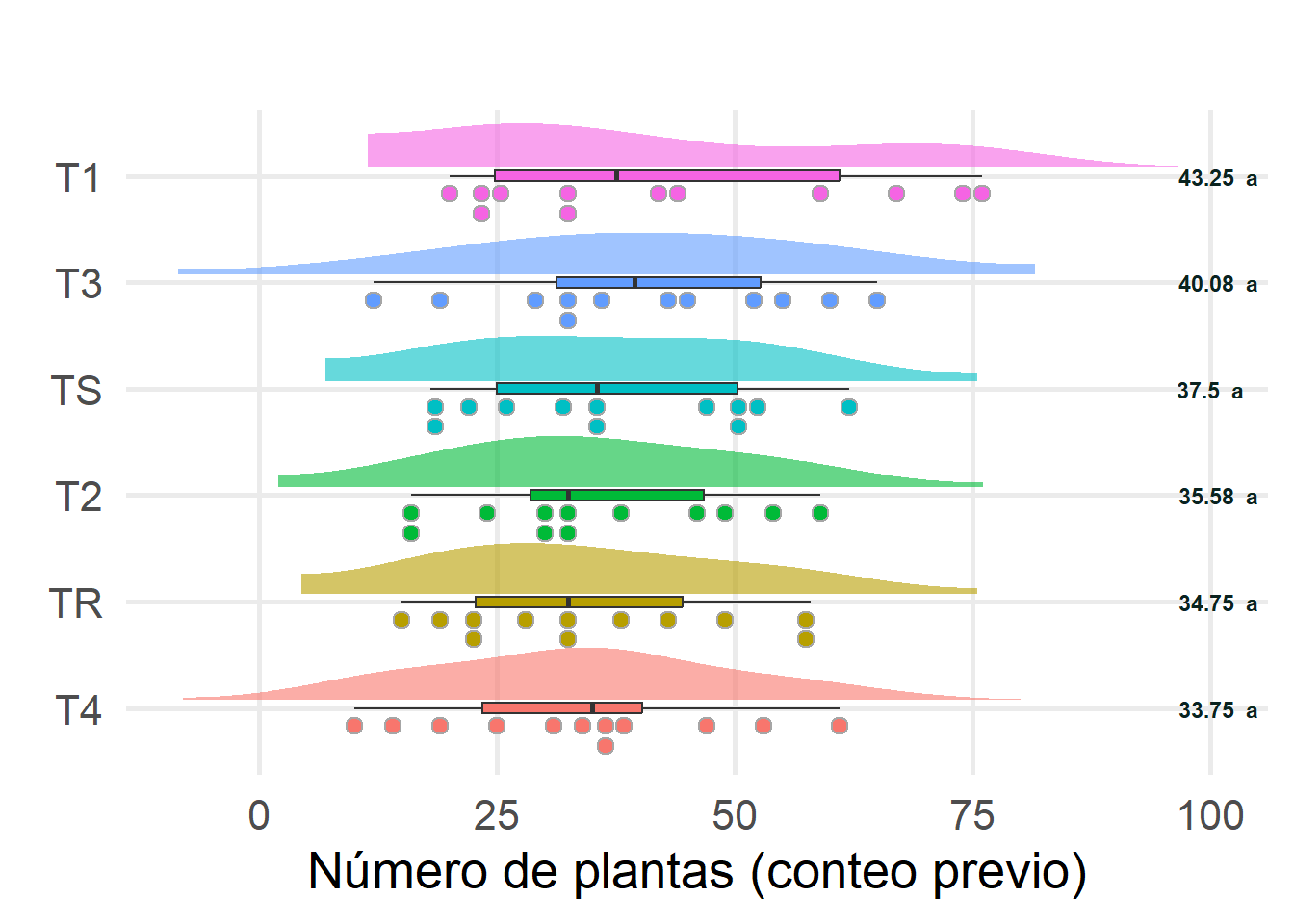
H.1.3 Resumen gráfico
Código
library(ggdist)library(ggtext)# Preparar los datos del test de Tukeytukey_groups <- tukey_results_transformed$groupstukey_groups$Tratamiento <-rownames(tukey_groups)rownames(tukey_groups) <-NULL# Unir los resultados del test de Tukey con los summary_statssummary_stats <- summary_stats %>%left_join(tukey_groups, by ="Tratamiento")# Ordenar el eje Y de manera descendentedata$Tratamiento <-factor(data$Tratamiento, levels = summary_stats$Tratamiento[order(summary_stats$media)])graficoNoPlantas0ddaTUKEY <- data %>%ggplot(aes(x=noPlantas0dda, y = Tratamiento, fill = Tratamiento)) +geom_boxplot(width =0.1) +geom_dots(side ='bottom',position =position_nudge(y =-0.075),height =0.55 ) +stat_slab(position =position_nudge(y =0.075),height =0.55,trim =FALSE,alpha =0.6 ) +labs(title="",y =element_blank(),x ="Número de plantas (conteo previo)" ) +theme_minimal(base_size =20)+theme(text =element_text(family ="montserrat"),panel.grid.minor =element_blank(),legend.position ='none' )+geom_text(data = summary_stats, aes(x =95, y = Tratamiento, label =paste0(round(media, 2), " ", groups)), hjust =-0.2, size =3, color ="#0a231fff", fontface ="bold", hjust =1)graficoNoPlantas0ddaTUKEY#ggsave("./Plots/graficoNoPlantas0ddaTUKEY.png", plot = graficoNoPlantas0ddaTUKEY, width=1920, height=1080, units = "px")
Tabla H.14: Gráfico de…
H.2 Conteo final (28 dda)
Descriptivo
Código
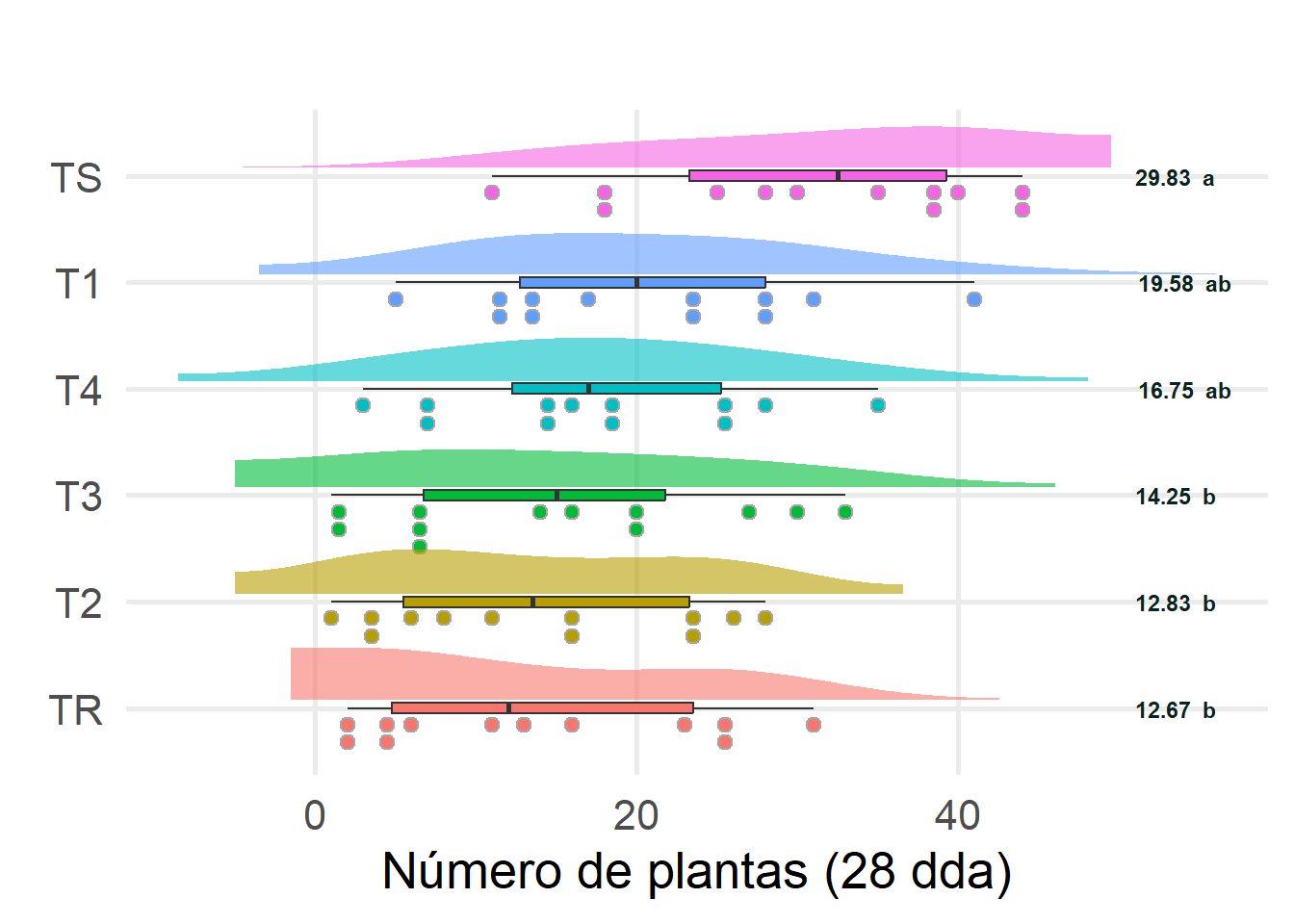
# Leer los datos desde el archivo Exceldata <-read_excel("csv/correlacionRendimiento.xlsx")# Mostrar una vista previa de los datos#head(data)# Convertir la columna 'Tratamiento' a factordata$Tratamiento <-as.factor(data$Tratamiento)# Análisis descriptivosummary_stats <- data %>%group_by(Tratamiento) %>%summarise(n =n(),media =mean(noPlantas28dda, na.rm =TRUE),mediana =median(noPlantas28dda, na.rm =TRUE),sd =sd(noPlantas28dda, na.rm =TRUE),varianza =var(noPlantas28dda, na.rm =TRUE),min =min(noPlantas28dda, na.rm =TRUE),max =max(noPlantas28dda, na.rm =TRUE))print(summary_stats)
# Análisis estadístico# Análisis de Varianza (ANOVA) considerando el efecto de Tratamiento y bloquemodel <-aov(noPlantas28dda ~ Tratamiento + bloque, data = data)anova_results <-Anova(model)# Mostrar los resultados del ANOVAprint(anova_results)
Shapiro-Wilk normality test
data: residuals(model)
W = 0.9629, p-value = 0.03228
Comparaciones múltiples
# Comparaciones múltiples usando el test de Tukeytukey_results <-HSD.test(model, "Tratamiento")# Mostrar los resultados del test de Tukeyprint(tukey_results)
$statistics
MSerror Df Mean CV MSD
107.4036 65 17.65278 58.70788 12.42378
$parameters
test name.t ntr StudentizedRange alpha
Tukey Tratamiento 6 4.152742 0.05
$means
noPlantas28dda std r se Min Max Q25 Q50 Q75
T1 19.58333 10.334922 12 2.991705 4 40 11.75 19.0 27.00
T2 12.83333 9.665622 12 2.991705 0 27 4.50 12.5 22.25
T3 14.25000 10.947187 12 2.991705 0 32 5.75 14.0 20.75
T4 16.75000 9.526279 12 2.991705 2 34 11.25 16.0 24.25
TR 12.66667 10.360180 12 2.991705 1 30 3.75 11.0 22.50
TS 29.83333 11.002754 12 2.991705 10 43 22.25 31.5 38.25
$comparison
NULL
$groups
noPlantas28dda groups
TS 29.83333 a
T1 19.58333 ab
T4 16.75000 b
T3 14.25000 b
T2 12.83333 b
TR 12.66667 b
attr(,"class")
[1] "group"
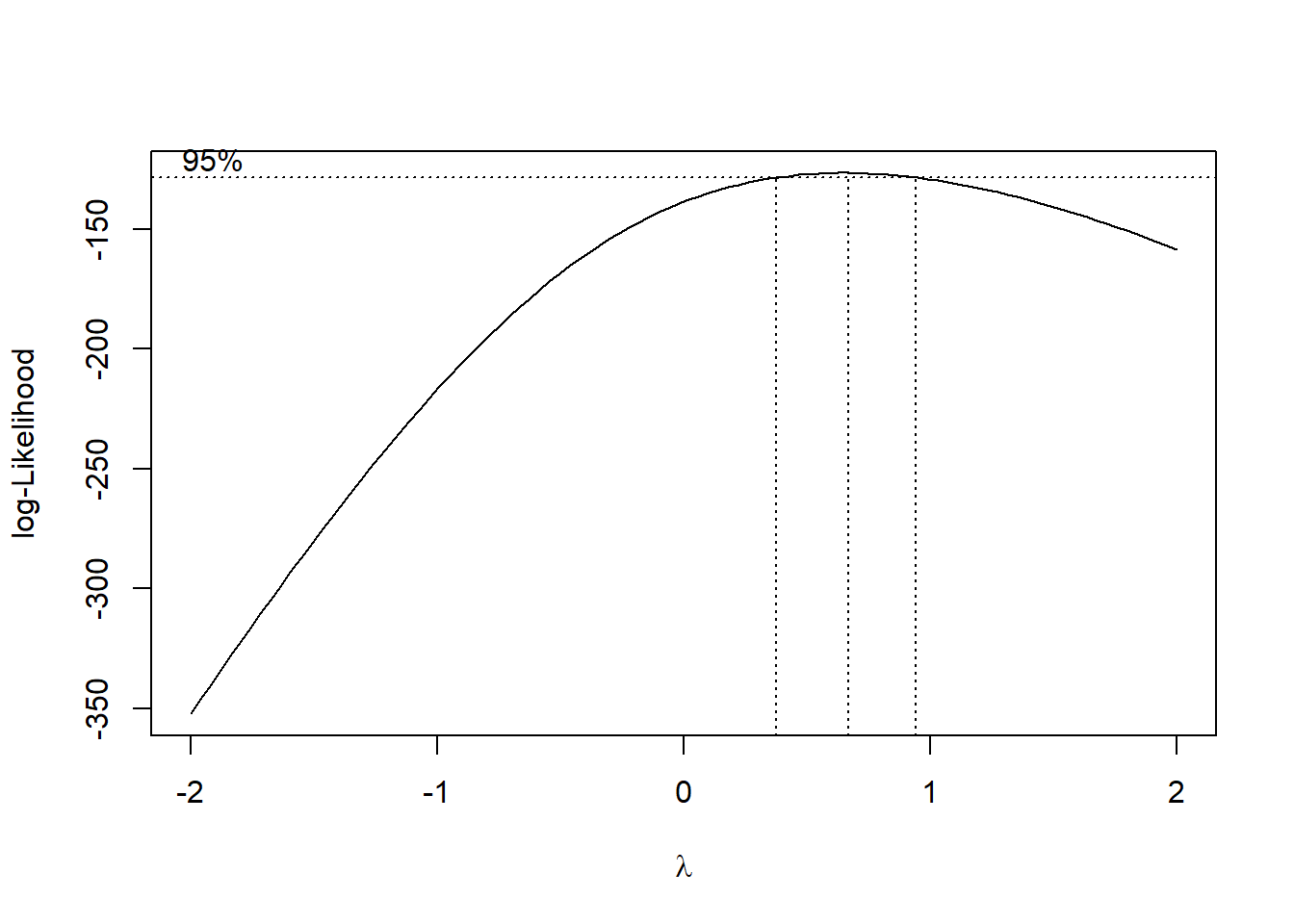
H.2.2 Transformación de Box-Cox
# Cargar las librerías necesariaslibrary(MASS)library(car)# Leer los datos desde el archivo Exceldata <-read_excel("csv/correlacionRendimiento.xlsx")# Convertir la columna 'Tratamiento' a factordata$Tratamiento <-as.factor(data$Tratamiento)data$noPlantas28dda <- data$noPlantas28dda +1# Aplicar la transformación de Box-Coxboxcox_results <-boxcox(noPlantas28dda ~ Tratamiento + bloque, data = data, lambda =seq(-2, 2, 0.1))
# Encontrar el mejor lambdabest_lambda <- boxcox_results$x[which.max(boxcox_results$y)]print(paste("Mejor lambda:", best_lambda))
[1] "Mejor lambda: 0.666666666666667"
# Transformar los datos usando el mejor lambdaif (best_lambda ==0) { data$transformed_noPlantas28dda <-log(data$noPlantas28dda)} else { data$transformed_noPlantas28dda <- (data$noPlantas28dda^best_lambda -1) / best_lambda}# Ajustar el modelo con los datos transformadosmodel_transformed <-aov(transformed_noPlantas28dda ~ Tratamiento + bloque, data = data)# Verificación de supuestos con los datos transformadosshapiro_test_transformed <-shapiro.test(residuals(model_transformed))levene_test_transformed <- car::leveneTest(transformed_noPlantas28dda ~ Tratamiento, data = data)# Resultados del modelo y verificación de supuestosanova_results_transformed <-Anova(model_transformed)print(anova_results_transformed)
Shapiro-Wilk normality test
data: residuals(model_transformed)
W = 0.9615, p-value = 0.02686
print(levene_test_transformed)
Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 5 0.4579 0.8061
66
# Análisis de independencia de los residuos transformadosplot(residuals(model_transformed) ~fitted(model_transformed))abline(h =0, col ="red")
# Comparaciones múltiples usando el test de Tukey en datos transformadostukey_results_transformed <-HSD.test(model_transformed, "Tratamiento")print(tukey_results_transformed)
$statistics
MSerror Df Mean CV MSD
17.24268 65 8.516729 48.75617 4.977906
$parameters
test name.t ntr StudentizedRange alpha
Tukey Tratamiento 6 4.152742 0.05
$means
transformed_noPlantas28dda std r se Min Max Q25
T1 9.458596 3.823438 12 1.198704 2.8860266 16.33530 6.685428
T2 6.619040 4.261813 12 1.198704 0.0000000 12.33131 3.159609
T3 7.130703 4.670202 12 1.198704 0.0000000 13.93241 3.854942
T4 8.359369 3.817102 12 1.198704 1.6201257 14.54981 6.407124
TR 6.503396 4.465421 12 1.198704 0.8811016 13.30241 2.734461
TS 13.029270 3.681345 12 1.198704 5.9191312 17.19504 10.694222
Q50 Q75
T1 9.524301 12.33131
T2 6.971769 10.71865
T3 7.618792 10.16407
T4 8.413417 11.40976
TR 6.356147 10.80473
TS 13.766076 15.82388
$comparison
NULL
$groups
transformed_noPlantas28dda groups
TS 13.029270 a
T1 9.458596 ab
T4 8.359369 ab
T3 7.130703 b
T2 6.619040 b
TR 6.503396 b
attr(,"class")
[1] "group"
H.2.3 Análisis no paramétrico
# Test de Kruskal-Walliskruskal_test <-kruskal.test(noPlantas28dda ~ Tratamiento, data = data)print(kruskal_test)
Kruskal-Wallis rank sum test
data: noPlantas28dda by Tratamiento
Kruskal-Wallis chi-squared = 16.333, df = 5, p-value = 0.005954
Test de Dunn
library(FSA)
Warning: package 'FSA' was built under R version 4.2.3
Registered S3 methods overwritten by 'FSA':
method from
confint.boot car
hist.boot car
## FSA v0.9.5. See citation('FSA') if used in publication.
## Run fishR() for related website and fishR('IFAR') for related book.
Attaching package: 'FSA'
The following object is masked from 'package:car':
bootCase
dunn_test <-dunnTest(noPlantas28dda ~ Tratamiento , data = data, method ="bonferroni")print(dunn_test)
library(ggdist)library(ggtext)# Preparar los datos del test de Tukeytukey_groups <- tukey_results_transformed$groupstukey_groups$Tratamiento <-rownames(tukey_groups)rownames(tukey_groups) <-NULL# Unir los resultados del test de Tukey con los summary_statssummary_stats <- summary_stats %>%left_join(tukey_groups, by ="Tratamiento")# Ordenar el eje Y de manera descendentedata$Tratamiento <-factor(data$Tratamiento, levels = summary_stats$Tratamiento[order(summary_stats$media)])graficoNoPlantas28ddaTUKEY <- data %>%ggplot(aes(x=noPlantas28dda, y = Tratamiento, fill = Tratamiento)) +geom_boxplot(width =0.1) +geom_dots(side ='bottom',position =position_nudge(y =-0.075),height =0.55 ) +stat_slab(position =position_nudge(y =0.075),height =0.55,trim =FALSE,alpha =0.6 ) +labs(title="",y =element_blank(),x ="Número de plantas (28 dda)" ) +theme_minimal(base_size =20)+theme(text =element_text(family ="montserrat"),panel.grid.minor =element_blank(),legend.position ='none' )+geom_text(data = summary_stats, aes(x =50, y = Tratamiento, label =paste0(round(media, 2), " ", groups)), hjust =-0.2, size =3, color ="#0a231fff", fontface ="bold", hjust =1)graficoNoPlantas28ddaTUKEY#ggsave("./Plots/graficoNoPlantas28ddaTUKEY.png", plot = graficoNoPlantas28ddaTUKEY, width=1920, height=1080, units = "px")
Tabla H.15: Gráfico de…
H.3 Cambio en número de plantas (28 dda)
Descriptivo
# Leer los datos desde el archivo Exceldata <-read_excel("csv/correlacionRendimiento.xlsx")# Mostrar una vista previa de los datoshead(data)
# Análisis estadístico# Análisis de Varianza (ANOVA) considerando el efecto de Tratamiento y bloquemodel <-aov(cambioNoPlantas ~ Tratamiento + bloque, data = data)anova_results <-Anova(model)# Mostrar los resultados del ANOVAprint(anova_results)
Shapiro-Wilk normality test
data: residuals(model)
W = 0.99027, p-value = 0.857
Comparaciones múltiples
# Comparaciones múltiples usando el test de Tukeytukey_results <-HSD.test(model, "Tratamiento")# Mostrar los resultados del test de Tukeyprint(tukey_results)
$statistics
MSerror Df Mean CV MSD
166.078 65 -19.83333 -64.97711 15.449
$parameters
test name.t ntr StudentizedRange alpha
Tukey Tratamiento 6 4.152742 0.05
$means
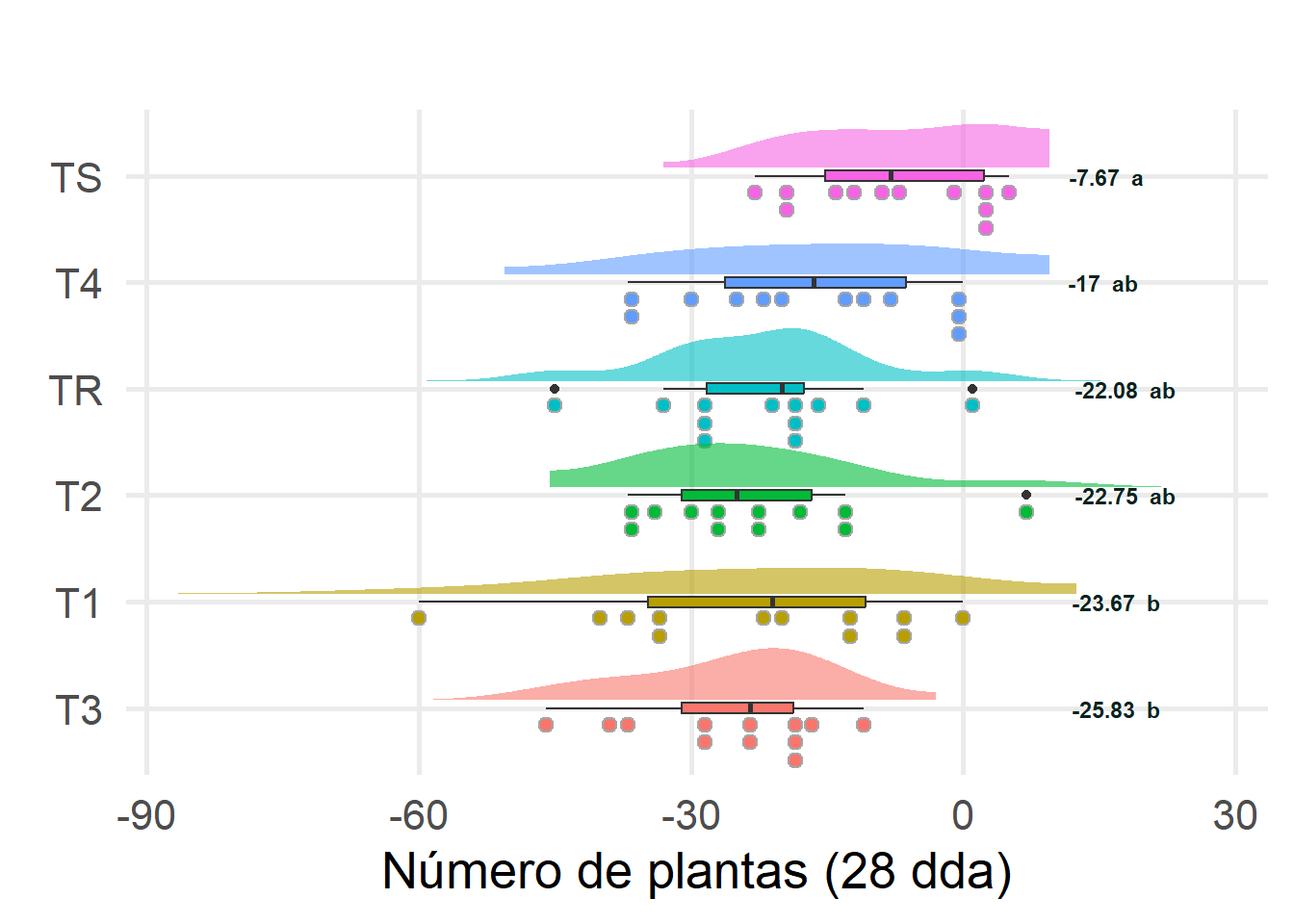
cambioNoPlantas std r se Min Max Q25 Q50 Q75
T1 -23.666667 17.51536 12 3.720193 -60 0 -34.75 -21.0 -10.75
T2 -22.750000 12.40326 12 3.720193 -37 7 -31.00 -25.0 -16.75
T3 -25.833333 10.37333 12 3.720193 -46 -11 -31.00 -23.5 -18.75
T4 -17.000000 13.35528 12 3.720193 -37 0 -26.25 -16.5 -6.25
TR -22.083333 11.67327 12 3.720193 -45 1 -28.25 -20.0 -17.50
TS -7.666667 10.01211 12 3.720193 -23 5 -15.25 -8.0 2.25
$comparison
NULL
$groups
cambioNoPlantas groups
TS -7.666667 a
T4 -17.000000 ab
TR -22.083333 ab
T2 -22.750000 ab
T1 -23.666667 b
T3 -25.833333 b
attr(,"class")
[1] "group"
H.3.2 Resumen gráfico
Código
#library(ggdist)#library(ggtext)# Preparar los datos del test de Tukeytukey_groups <- tukey_results$groupstukey_groups$Tratamiento <-rownames(tukey_groups)rownames(tukey_groups) <-NULL# Unir los resultados del test de Tukey con los summary_statssummary_stats <- summary_stats %>%left_join(tukey_groups, by ="Tratamiento")# Ordenar el eje Y de manera descendentedata$Tratamiento <-factor(data$Tratamiento, levels = summary_stats$Tratamiento[order(summary_stats$media)])graficocambioNoPlantasTUKEY <- data %>%ggplot(aes(x=cambioNoPlantas, y = Tratamiento, fill = Tratamiento)) +geom_boxplot(width =0.1) +geom_dots(side ='bottom',position =position_nudge(y =-0.075),height =0.55 ) +stat_slab(position =position_nudge(y =0.075),height =0.55,trim =FALSE,alpha =0.6 ) +labs(title="",y =element_blank(),x ="Número de plantas (28 dda)" ) +theme_minimal(base_size =20)+theme(text =element_text(family ="montserrat"),panel.grid.minor =element_blank(),legend.position ='none' )+geom_text(data = summary_stats, aes(x =10, y = Tratamiento, label =paste0(round(media, 2), " ", groups)), hjust =-0.2, size =3, color ="#0a231fff", fontface ="bold", hjust =1)graficocambioNoPlantasTUKEY#ggsave("./Plots/graficocambioNoPlantasTUKEY.png", plot = graficocambioNoPlantasTUKEY, width=1920, height=1080, units = "px")
Tabla H.16: Gráfico de…
H.4 Altura máxima (0 dda)
Descriptivo
# Leer los datos desde el archivo Exceldata <-read_excel("csv/correlacionRendimiento.xlsx")# Mostrar una vista previa de los datoshead(data)
# Análisis estadístico# Análisis de Varianza (ANOVA) considerando el efecto de Tratamiento y bloquemodel <-aov(hMax0dda ~ Tratamiento + bloque, data = data)anova_results <-Anova(model)# Mostrar los resultados del ANOVAprint(anova_results)
Shapiro-Wilk normality test
data: residuals(model)
W = 0.97751, p-value = 0.2241
Comparaciones múltiples
# Comparaciones múltiples usando el test de Tukeytukey_results <-HSD.test(model, "Tratamiento")# Mostrar los resultados del test de Tukeyprint(tukey_results)
$statistics
MSerror Df Mean CV MSD
20.53844 65 18.33333 24.71965 5.432854
$parameters
test name.t ntr StudentizedRange alpha
Tukey Tratamiento 6 4.152742 0.05
$means
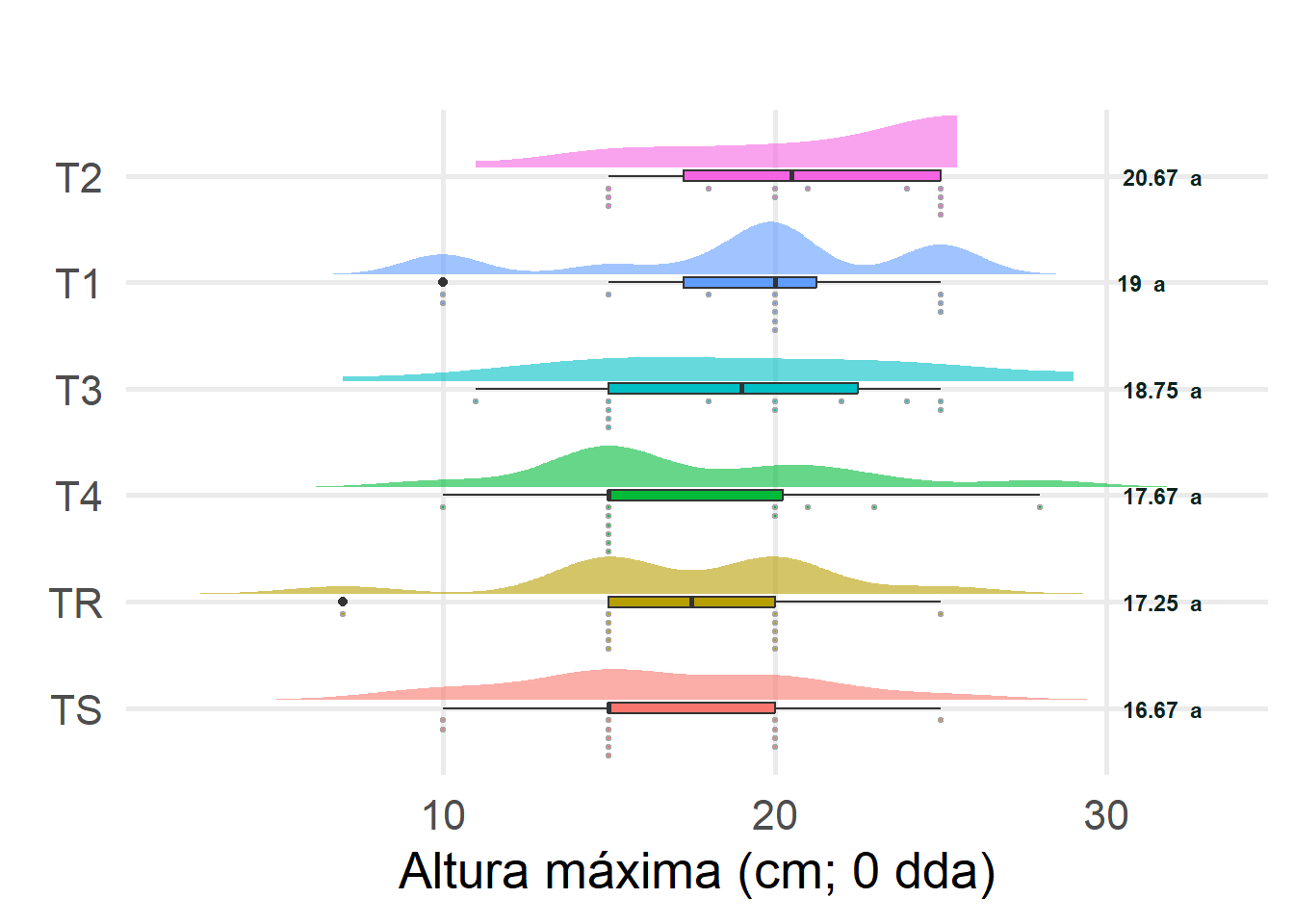
hMax0dda std r se Min Max Q25 Q50 Q75
T1 19.00000 5.152228 12 1.308257 10 25 17.25 20.0 21.25
T2 20.66667 4.163332 12 1.308257 15 25 17.25 20.5 25.00
T3 18.75000 4.634358 12 1.308257 11 25 15.00 19.0 22.50
T4 17.66667 4.849242 12 1.308257 10 28 15.00 15.0 20.25
TR 17.25000 4.555217 12 1.308257 7 25 15.00 17.5 20.00
TS 16.66667 4.438127 12 1.308257 10 25 15.00 15.0 20.00
$comparison
NULL
$groups
hMax0dda groups
T2 20.66667 a
T1 19.00000 a
T3 18.75000 a
T4 17.66667 a
TR 17.25000 a
TS 16.66667 a
attr(,"class")
[1] "group"
H.4.2 Resumen gráfico
Código
#library(ggdist)#library(ggtext)# Preparar los datos del test de Tukeytukey_groups <- tukey_results$groupstukey_groups$Tratamiento <-rownames(tukey_groups)rownames(tukey_groups) <-NULL# Unir los resultados del test de Tukey con los summary_statssummary_stats <- summary_stats %>%left_join(tukey_groups, by ="Tratamiento")# Ordenar el eje Y de manera descendentedata$Tratamiento <-factor(data$Tratamiento, levels = summary_stats$Tratamiento[order(summary_stats$media)])graficohMax0ddaTUKEY <- data %>%ggplot(aes(x=hMax0dda, y = Tratamiento, fill = Tratamiento)) +geom_boxplot(width =0.1) +geom_dots(side ='bottom',position =position_nudge(y =-0.075),height =0.55 ) +stat_slab(position =position_nudge(y =0.075),height =0.55,trim =FALSE,alpha =0.6 ) +labs(title="",y =element_blank(),x ="Altura máxima (cm; 0 dda)" ) +theme_minimal(base_size =20)+theme(text =element_text(family ="montserrat"),panel.grid.minor =element_blank(),legend.position ='none' )+geom_text(data = summary_stats, aes(x =30, y = Tratamiento, label =paste0(round(media, 2), " ", groups)), hjust =-0.2, size =3, color ="#0a231fff", fontface ="bold", hjust =1)graficohMax0ddaTUKEYggsave("./Plots/graficohMax0ddaTUKEY.png", plot = graficohMax0ddaTUKEY, width=1920, height=1080, units ="px")
Tabla H.17: Gráfico de…
H.5 Altura máxima (28 dda)
Descriptivo
# Leer los datos desde el archivo Exceldata <-read_excel("csv/correlacionRendimiento.xlsx")# Mostrar una vista previa de los datoshead(data)
# Análisis estadístico# Análisis de Varianza (ANOVA) considerando el efecto de Tratamiento y bloquemodel <-aov(hMax28dda ~ Tratamiento + bloque, data = data)anova_results <-Anova(model)# Mostrar los resultados del ANOVAprint(anova_results)
Shapiro-Wilk normality test
data: residuals(model)
W = 0.99401, p-value = 0.9831
Análisis de homogeneidad de varianzas utilizando la prueba de Levene
levene_test <- car::leveneTest(hMax28dda ~ Tratamiento, data = data)print(levene_test)
Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 5 1.0018 0.4237
66
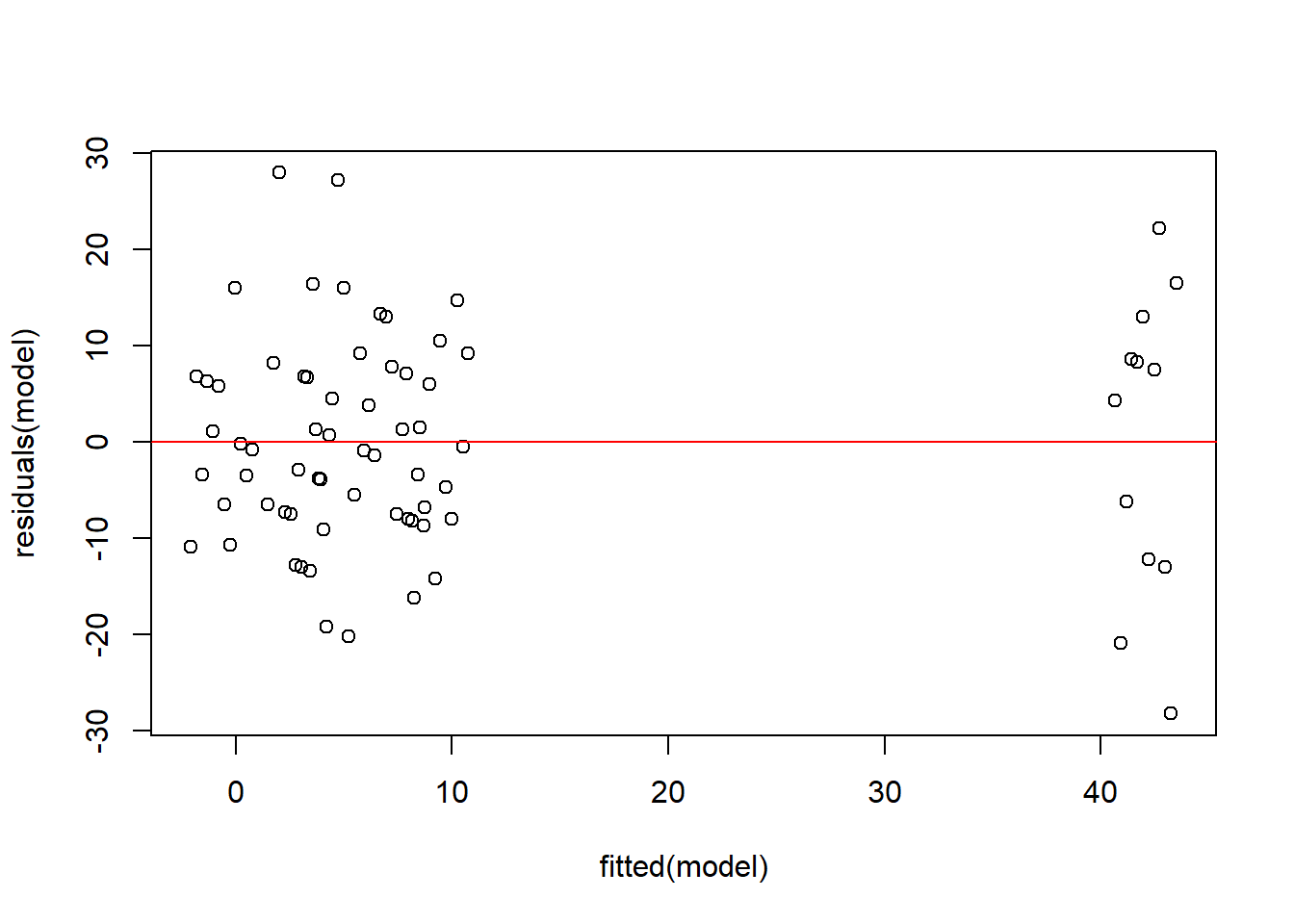
Análisis de independencia de los residuos
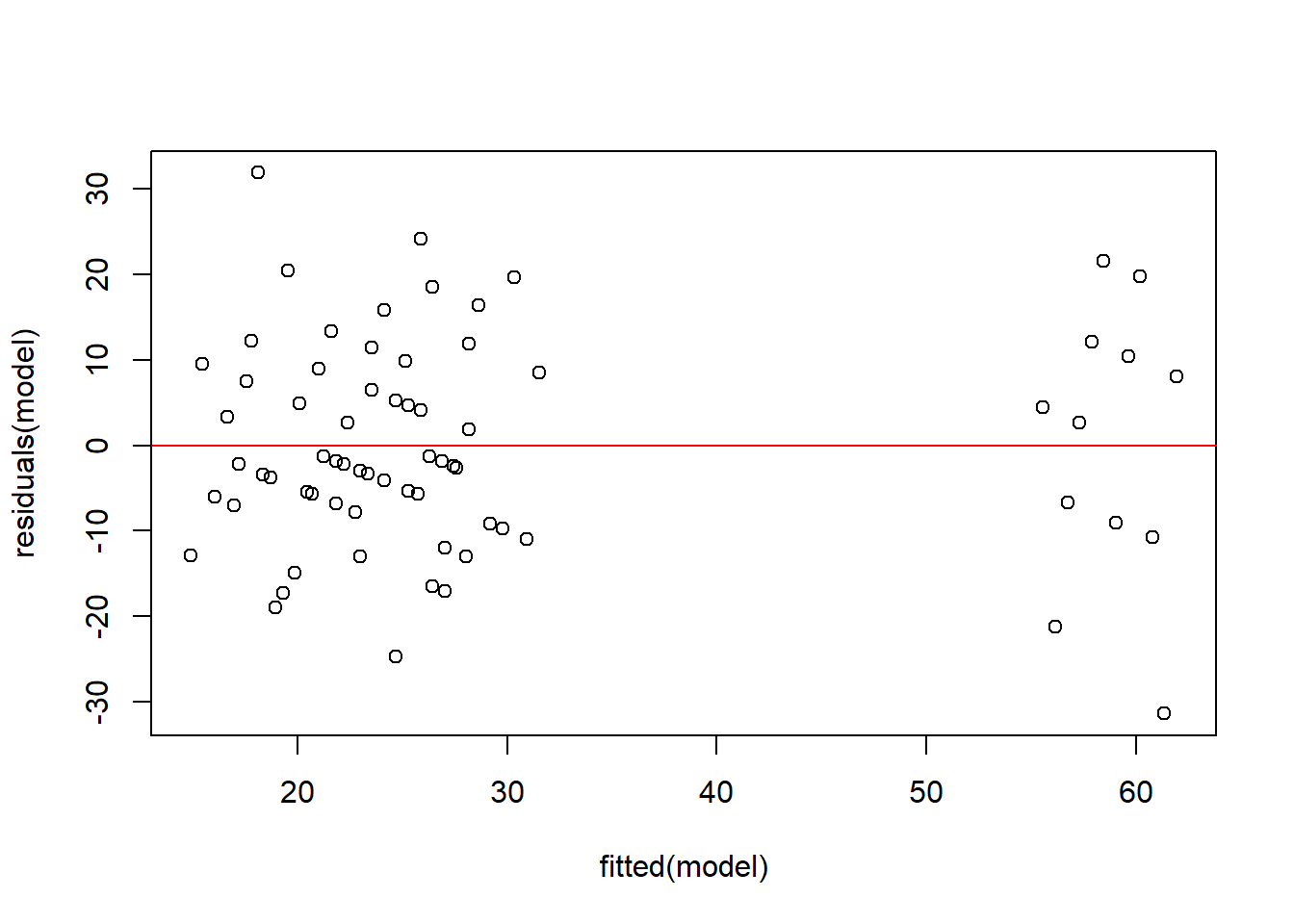
plot(residuals(model) ~fitted(model))abline(h =0, col ="red")
Comparaciones múltiples
# Comparaciones múltiples usando el test de Tukeytukey_results <-HSD.test(model, "Tratamiento")# Mostrar los resultados del test de Tukeyprint(tukey_results)
$statistics
MSerror Df Mean CV MSD
164.8426 65 29.22222 43.9361 15.39143
$parameters
test name.t ntr StudentizedRange alpha
Tukey Tratamiento 6 4.152742 0.05
$means
hMax28dda std r se Min Max Q25 Q50 Q75
T1 28.33333 11.348475 12 3.70633 15 50 20.00 25.0 36.25
T2 25.00000 15.075567 12 3.70633 0 50 13.75 25.0 32.50
T3 18.08333 11.301314 12 3.70633 0 40 13.75 17.5 25.00
T4 25.00000 8.528029 12 3.70633 10 40 20.00 25.0 30.00
TR 20.16667 13.394933 12 3.70633 2 50 13.75 17.5 26.25
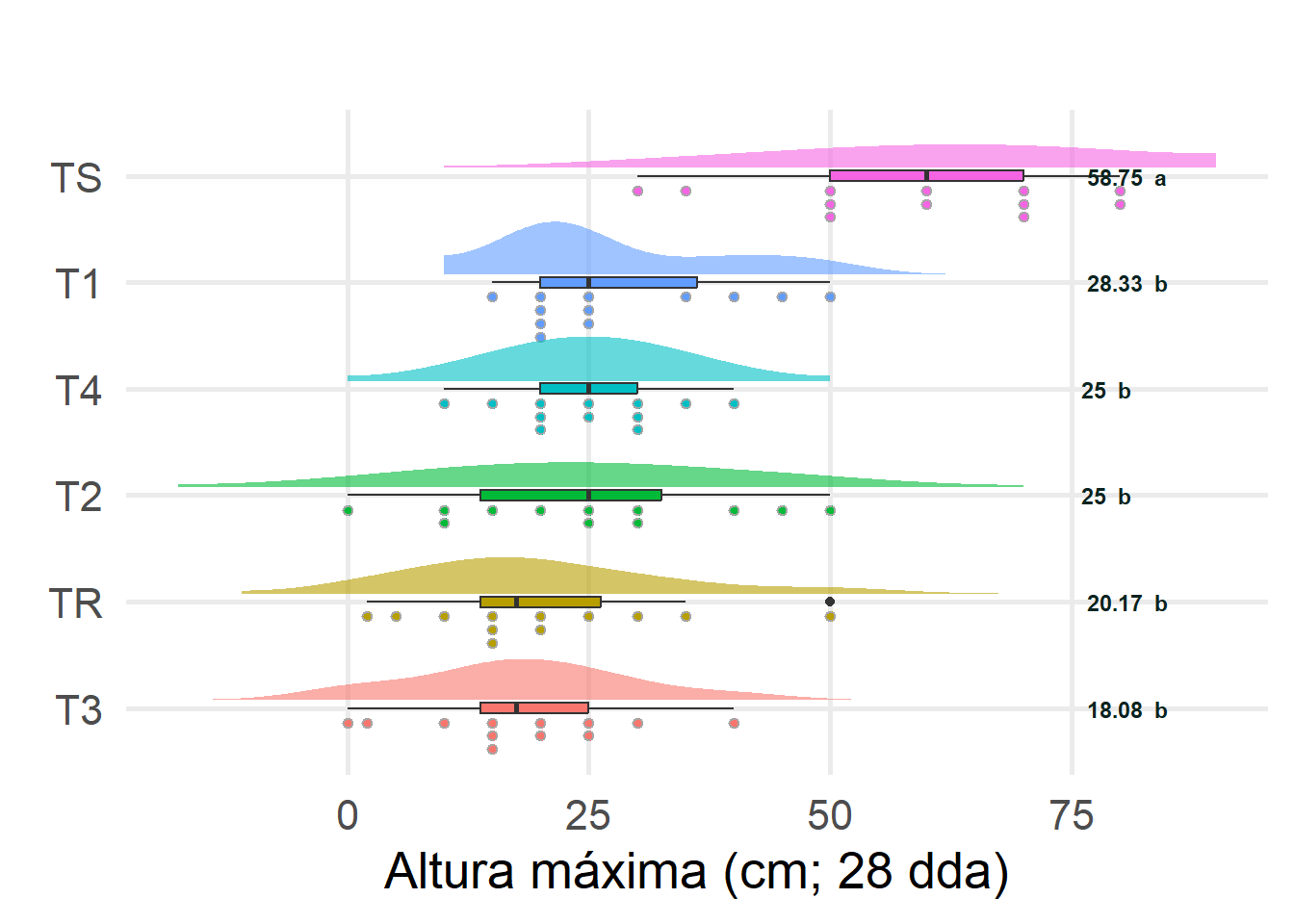
TS 58.75000 16.254370 12 3.70633 30 80 50.00 60.0 70.00
$comparison
NULL
$groups
hMax28dda groups
TS 58.75000 a
T1 28.33333 b
T2 25.00000 b
T4 25.00000 b
TR 20.16667 b
T3 18.08333 b
attr(,"class")
[1] "group"
H.5.2 Resumen gráfico
Código
#library(ggdist)#library(ggtext)# Preparar los datos del test de Tukeytukey_groups <- tukey_results$groupstukey_groups$Tratamiento <-rownames(tukey_groups)rownames(tukey_groups) <-NULL# Unir los resultados del test de Tukey con los summary_statssummary_stats <- summary_stats %>%left_join(tukey_groups, by ="Tratamiento")# Ordenar el eje Y de manera descendentedata$Tratamiento <-factor(data$Tratamiento, levels = summary_stats$Tratamiento[order(summary_stats$media)])graficohMax28ddaTUKEY <- data %>%ggplot(aes(x=hMax28dda, y = Tratamiento, fill = Tratamiento)) +geom_boxplot(width =0.1) +geom_dots(side ='bottom',position =position_nudge(y =-0.075),height =0.55 ) +stat_slab(position =position_nudge(y =0.075),height =0.55,trim =FALSE,alpha =0.6 ) +labs(title="",y =element_blank(),x ="Altura máxima (cm; 28 dda)" ) +theme_minimal(base_size =20)+theme(text =element_text(family ="montserrat"),panel.grid.minor =element_blank(),legend.position ='none' )+geom_text(data = summary_stats, aes(x =75, y = Tratamiento, label =paste0(round(media, 2), " ", groups)), hjust =-0.2, size =3, color ="#0a231fff", fontface ="bold", hjust =1)graficohMax28ddaTUKEY#ggsave("./Plots/graficohMax28ddaTUKEY.png", plot = graficohMax28ddaTUKEY, width=1920, height=1080, units = "px")
Tabla H.18: Gráfico de…
H.6 Cambio en Altura máxima (28 dda)
Descriptivo
# Leer los datos desde el archivo Exceldata <-read_excel("csv/correlacionRendimiento.xlsx")# Mostrar una vista previa de los datoshead(data)
# Análisis estadístico# Análisis de Varianza (ANOVA) considerando el efecto de Tratamiento y bloquemodel <-aov(cambioAltura ~ Tratamiento + bloque, data = data)anova_results <-Anova(model)# Mostrar los resultados del ANOVAprint(anova_results)
Shapiro-Wilk normality test
data: residuals(model)
W = 0.99064, p-value = 0.8753
Análisis de homogeneidad de varianzas utilizando la prueba de Levene
levene_test <- car::leveneTest(cambioAltura ~ Tratamiento, data = data)print(levene_test)
Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 5 1.5362 0.1907
66
Análisis de independencia de los residuos
plot(residuals(model) ~fitted(model))abline(h =0, col ="red")
Comparaciones múltiples
# Comparaciones múltiples usando el test de Tukeytukey_results <-HSD.test(model, "Tratamiento")# Mostrar los resultados del test de Tukeyprint(tukey_results)
$statistics
MSerror Df Mean CV MSD
140.6932 65 10.88889 108.9314 14.21939
$parameters
test name.t ntr StudentizedRange alpha
Tukey Tratamiento 6 4.152742 0.05
$means
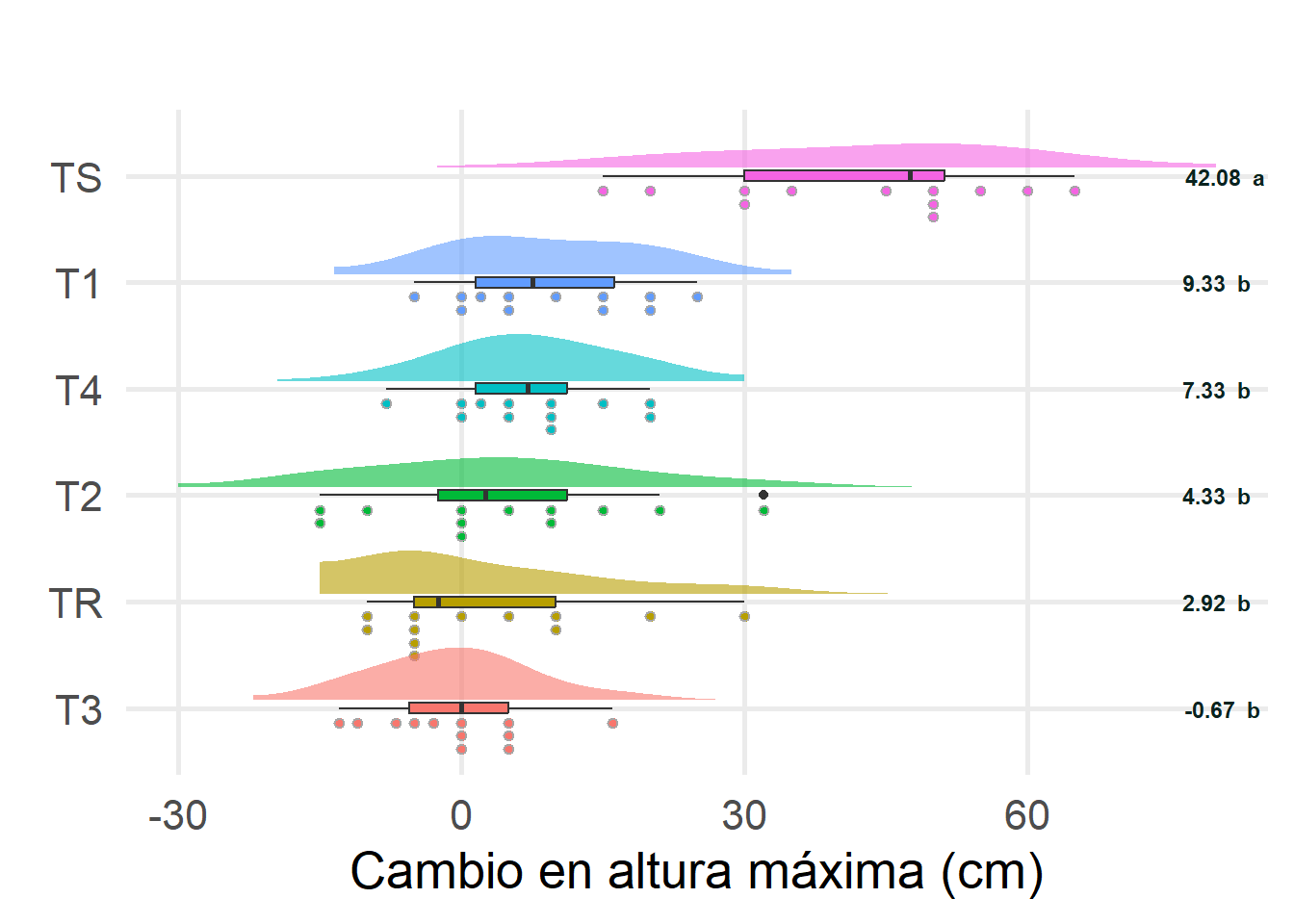
cambioAltura std r se Min Max Q25 Q50 Q75
T1 9.3333333 9.575853 12 3.424096 -5 25 1.5 7.5 16.25
T2 4.3333333 14.208406 12 3.424096 -15 32 -2.5 2.5 11.25
T3 -0.6666667 7.969639 12 3.424096 -13 16 -5.5 0.0 5.00
T4 7.3333333 8.413553 12 3.424096 -8 20 1.5 7.0 11.25
TR 2.9166667 12.515142 12 3.424096 -10 30 -5.0 -2.5 10.00
TS 42.0833333 15.877132 12 3.424096 15 65 30.0 47.5 51.25
$comparison
NULL
$groups
cambioAltura groups
TS 42.0833333 a
T1 9.3333333 b
T4 7.3333333 b
T2 4.3333333 b
TR 2.9166667 b
T3 -0.6666667 b
attr(,"class")
[1] "group"
Código
library(ggdist)library(ggtext)# Preparar los datos del test de Tukeytukey_groups <- tukey_results$groupstukey_groups$Tratamiento <-rownames(tukey_groups)rownames(tukey_groups) <-NULL# Unir los resultados del test de Tukey con los summary_statssummary_stats <- summary_stats %>%left_join(tukey_groups, by ="Tratamiento")# Ordenar el eje Y de manera descendentedata$Tratamiento <-factor(data$Tratamiento, levels = summary_stats$Tratamiento[order(summary_stats$media)])data %>%ggplot(aes(x=cambioAltura, y = Tratamiento, fill = Tratamiento)) +geom_boxplot(width =0.1) +geom_dots(side ='bottom',position =position_nudge(y =-0.075),height =0.55 ) +stat_slab(position =position_nudge(y =0.075),height =0.55,trim =FALSE,alpha =0.6 ) +labs(title="",y =element_blank(),x ="Cambio en altura máxima (cm)" ) +theme_minimal(base_size =20)+theme(text =element_text(family ="montserrat"),panel.grid.minor =element_blank(),legend.position ='none' )+geom_text(data = summary_stats, aes(x =75, y = Tratamiento, label =paste0(round(media, 2), " ", groups)), hjust =-0.2, size =3, color ="#0a231fff", fontface ="bold", hjust =1)
Tabla H.19: Gráfico de…
H.6.2 Gráfico de barras
Código
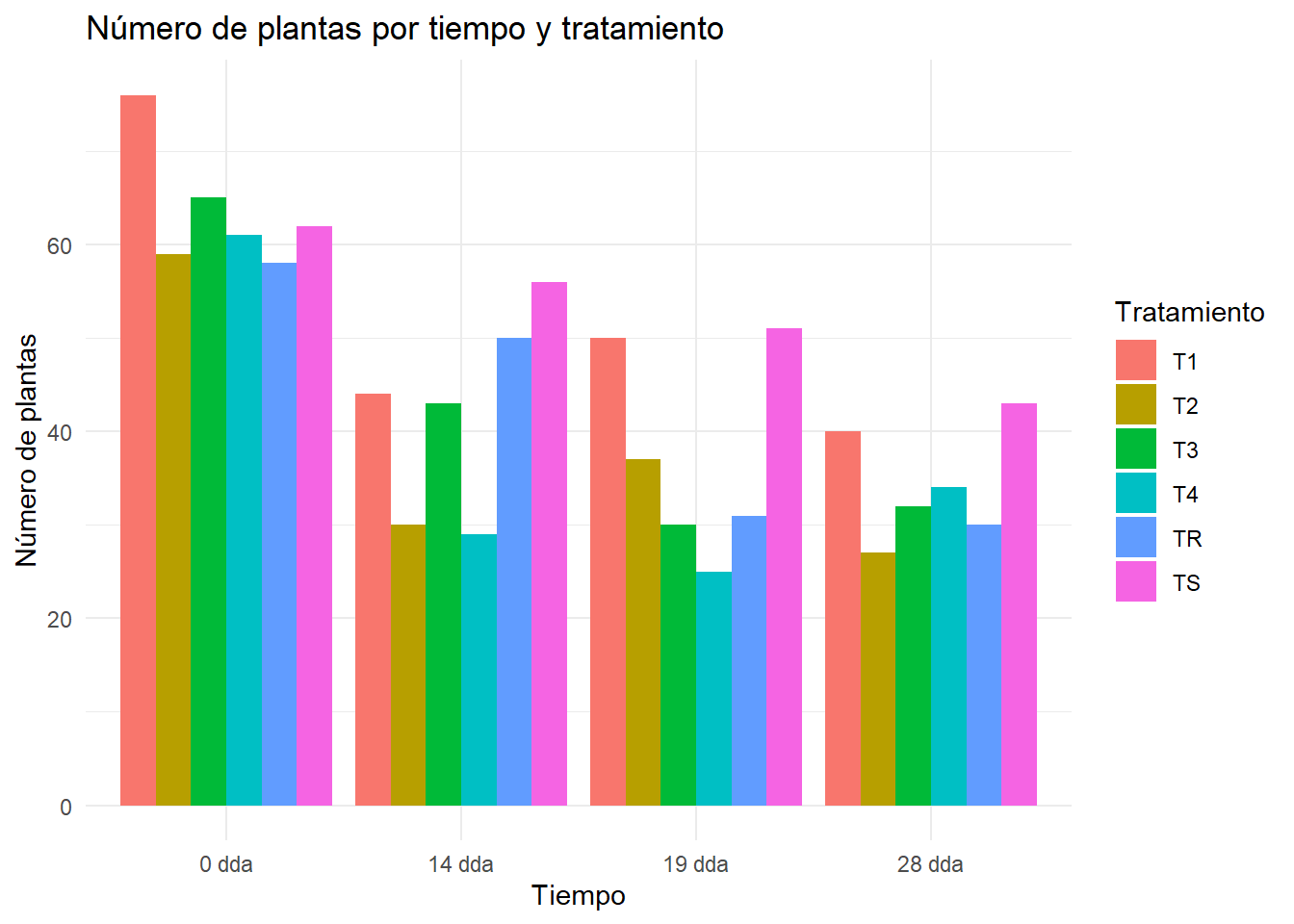
# Cargar las librerías necesariaslibrary(ggplot2)library(reshape2)# Cargar los datos desde el archivo Exceldf <-read_excel("csv/correlacionRendimiento.xlsx")# Filtrar las columnas relevantesdf_filtered <- df[, c("Tratamiento", "noPlantas0dda", "noPlantas14dda", "noPlantas19dda", "noPlantas28dda")]# Renombrar las columnas para que tengan las etiquetas deseadascolnames(df_filtered) <-c("Tratamiento", "0 dda", "14 dda", "19 dda", "28 dda")# Convertir el dataframe a formato largodf_melted <-melt(df_filtered, id.vars ="Tratamiento", variable.name ="Tiempo", value.name ="NoPlantas")# Crear el gráficofiguraBarrasNoplantas <-ggplot(df_melted, aes(x = Tiempo, y = NoPlantas, fill = Tratamiento)) +geom_bar(stat ="identity", position ="dodge") +labs(title ="Número de plantas por tiempo y tratamiento",x ="Tiempo", y ="Número de plantas") +theme_minimal()figuraBarrasNoplantas#ggsave("./Plots/figuraBarrasNoplantas.png", plot = figuraBarrasNoplantas, width=1920, height=1080, units = "px")
Tabla H.20: Gráfico de…
Código
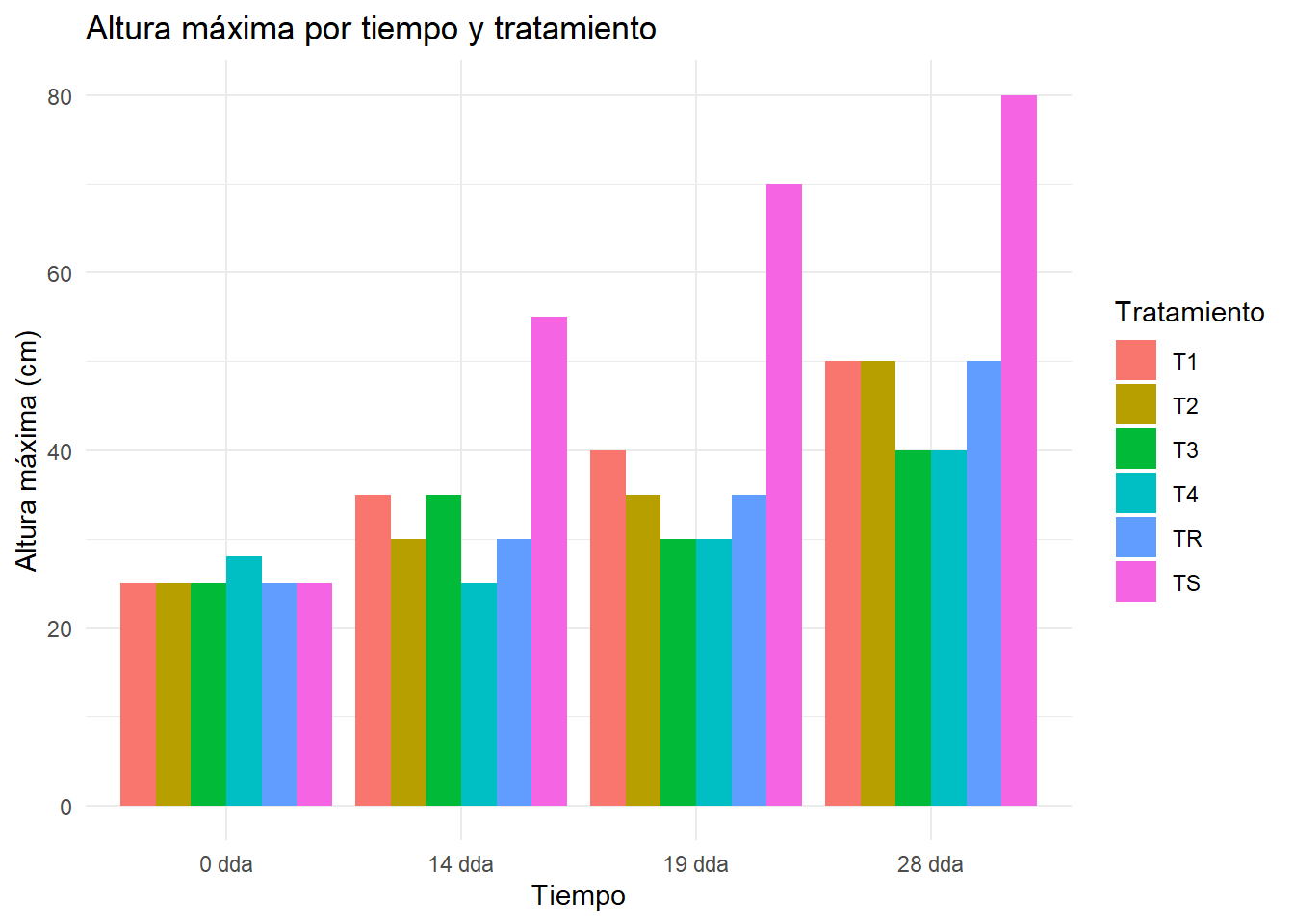
# Filtrar las columnas relevantesdf_filtered_hmax <- df[, c("Tratamiento", "hMax0dda", "hMax14dda", "hMax19dda", "hMax28dda")]# Renombrar las columnas para que tengan las etiquetas deseadascolnames(df_filtered_hmax) <-c("Tratamiento", "0 dda", "14 dda", "19 dda", "28 dda")# Convertir el dataframe a formato largodf_melted_hmax <-melt(df_filtered_hmax, id.vars ="Tratamiento", variable.name ="Tiempo", value.name ="hMax")# Crear el gráficofiguraBarrashMax <-ggplot(df_melted_hmax, aes(x = Tiempo, y = hMax, fill = Tratamiento)) +geom_bar(stat ="identity", position ="dodge") +labs(title ="Altura máxima por tiempo y tratamiento",x ="Tiempo", y ="Altura máxima (cm)") +theme_minimal()figuraBarrashMax#ggsave("./Plots/figuraBarrashMax.png", plot = figuraBarrashMax, width=1920, height=1080, units = "px")
Tabla H.21: Gráfico de…
Código
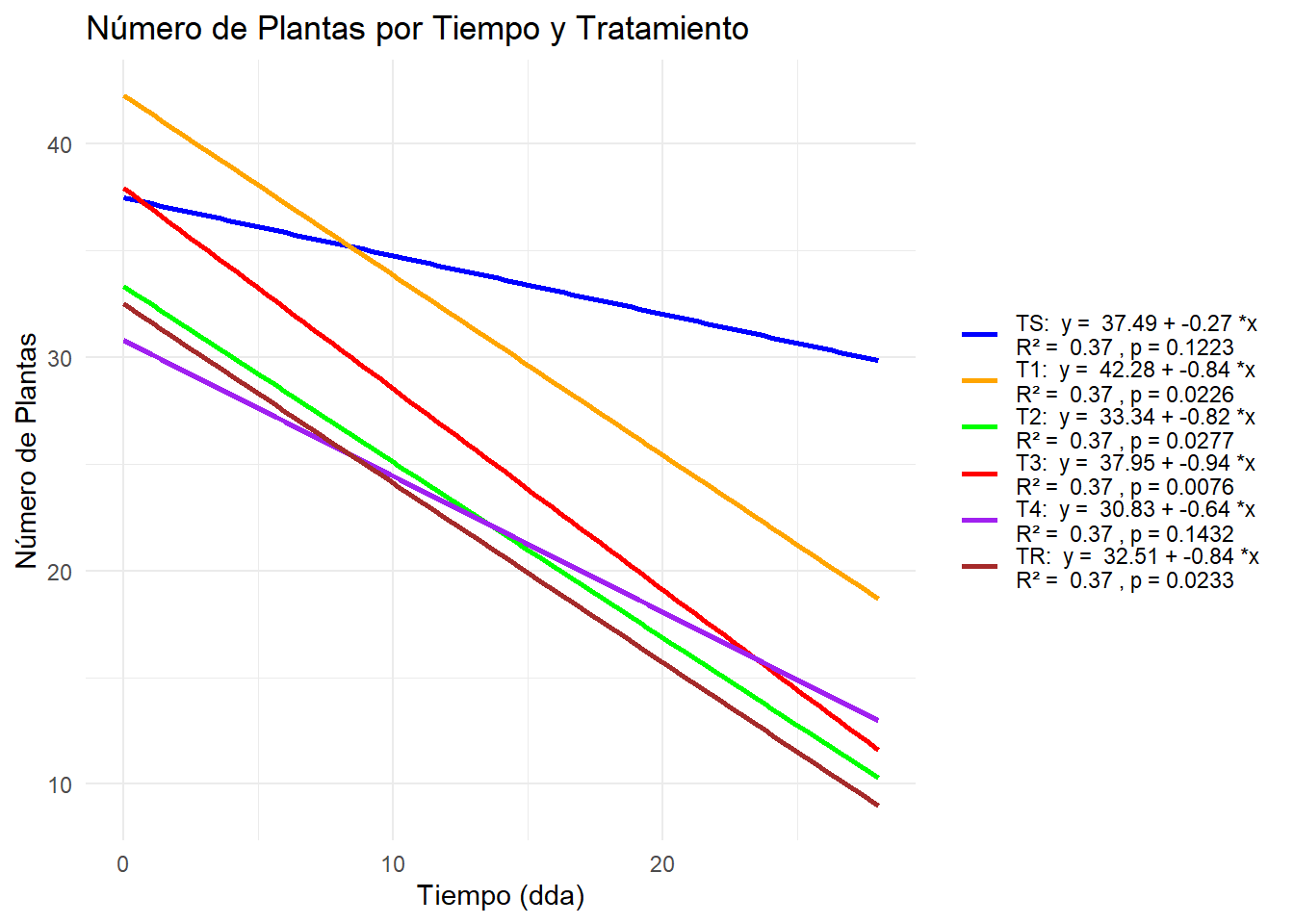
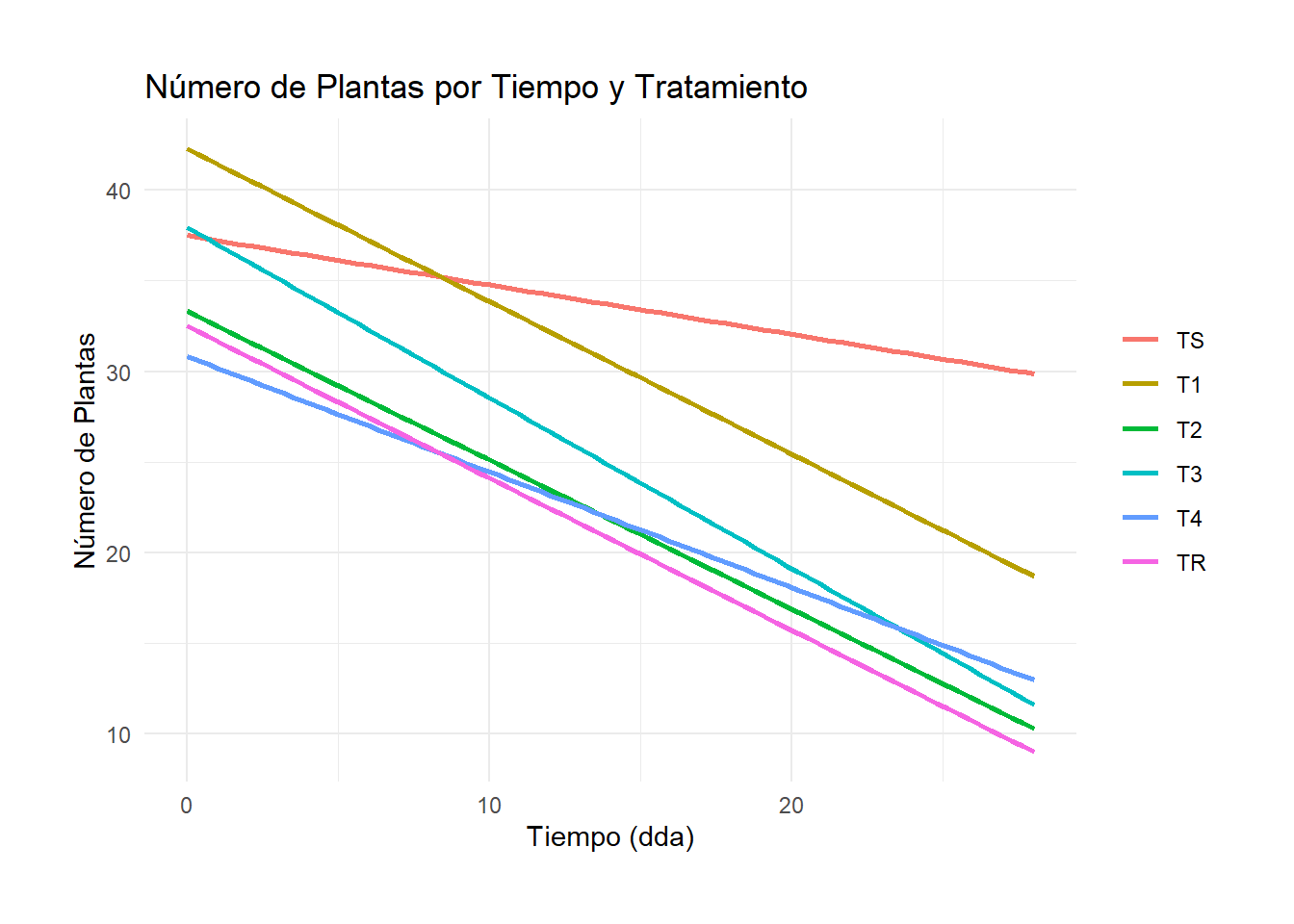
# Filtrar las columnas relevantesdf_filtered <- df[, c("Tratamiento", "noPlantas0dda", "noPlantas14dda", "noPlantas19dda", "noPlantas28dda")]# Renombrar las columnas para que tengan las etiquetas deseadascolnames(df_filtered) <-c("Tratamiento", "0 dda", "14 dda", "19 dda", "28 dda")# Convertir el dataframe a formato largodf_melted <-melt(df_filtered, id.vars ="Tratamiento", variable.name ="Tiempo", value.name ="NoPlantas")# Convertir la columna Tiempo a numérica para la regresióndf_melted$Tiempo <-as.numeric(gsub(" dda", "", df_melted$Tiempo))# Convertir Tratamiento a factor y especificar el nivel de referenciadf_melted$Tratamiento <-relevel(factor(df_melted$Tratamiento), ref ="TS")# Ajustar modelos lineales para cada tratamientomodels <-lm(NoPlantas ~ Tiempo * Tratamiento, data = df_melted)summary(models)
# Obtener coeficientes y estadísticosmodel_info <-tidy(models)# Crear etiquetas personalizadas para la leyendalabels <-c("TS"=paste("TS: ", "y = ", round(coef(models)[1], 2), "+", round(coef(models)[2], 2), "*x", "\nR² = ", round(summary(models)$r.squared, 2), ", p =", round(summary(models)$coefficients[2,4], 4)),"T1"=paste("T1: ", "y = ", round(coef(models)[1] +coef(models)[3], 2), "+", round(coef(models)[2] +coef(models)[8], 2), "*x", "\nR² = ", round(summary(models)$r.squared, 2), ", p =", round(summary(models)$coefficients[8,4], 4)),"T2"=paste("T2: ", "y = ", round(coef(models)[1] +coef(models)[4], 2), "+", round(coef(models)[2] +coef(models)[9], 2), "*x", "\nR² = ", round(summary(models)$r.squared, 2), ", p =", round(summary(models)$coefficients[9,4], 4)),"T3"=paste("T3: ", "y = ", round(coef(models)[1] +coef(models)[5], 2), "+", round(coef(models)[2] +coef(models)[10], 2), "*x", "\nR² = ", round(summary(models)$r.squared, 2), ", p =", round(summary(models)$coefficients[10,4], 4)),"T4"=paste("T4: ", "y = ", round(coef(models)[1] +coef(models)[6], 2), "+", round(coef(models)[2] +coef(models)[11], 2), "*x", "\nR² = ", round(summary(models)$r.squared, 2), ", p =", round(summary(models)$coefficients[11,4], 4)),"TR"=paste("TR: ", "y = ", round(coef(models)[1] +coef(models)[7], 2), "+", round(coef(models)[2] +coef(models)[12], 2), "*x", "\nR² = ", round(summary(models)$r.squared, 2), ", p =", round(summary(models)$coefficients[12,4], 4)))# Crear el gráfico con las etiquetas personalizadasfiguraRegresionNoPlantas <-ggplot(df_melted, aes(x = Tiempo, y = NoPlantas, color = Tratamiento, shape = Tratamiento)) +geom_smooth(method ="lm", se =FALSE) +# Líneas de regresiónlabs(title ="Número de Plantas por Tiempo y Tratamiento",x ="Tiempo (dda)", y ="Número de Plantas") +scale_color_manual(values =c("blue", "orange", "green", "red", "purple", "brown"), labels = labels) +scale_shape_manual(values =c(16, 17, 18, 19, 20, 21), labels = labels) +theme_minimal() +theme(legend.title =element_blank())figuraRegresionNoPlantas#ggsave("./Plots/figuraBarrashMax.png", plot = figuraBarrashMax, width=1920, height=1080, units = "px")# Crear el gráfico con solo las líneas de regresiónfiguraRegresionLineas <-ggplot(df_melted, aes(x = Tiempo, y = NoPlantas, color = Tratamiento)) +geom_smooth(method ="lm", se =FALSE, fullrange =TRUE) +# Solo líneas de regresiónlabs(title ="Número de Plantas por Tiempo y Tratamiento",x ="Tiempo (dda)", y ="Número de Plantas") +theme_minimal() +theme(legend.title =element_blank(),legend.position ="right", # Colocar la leyenda a la derechaplot.margin =margin(1, 1, 1, 1, "cm")) # Márgenes alrededor del gráficofiguraRegresionLineas
Tabla H.22: Gráfico de…
Código
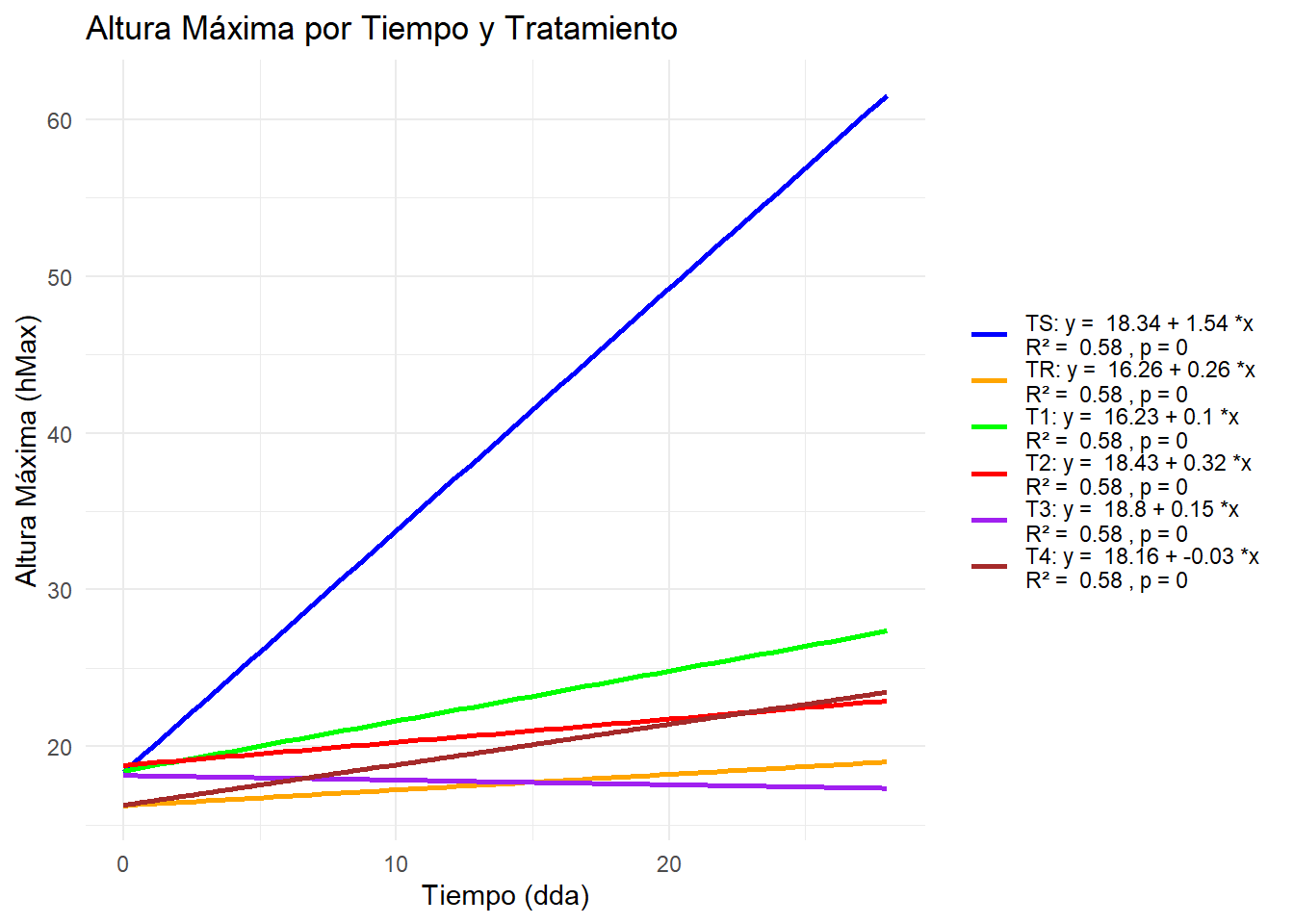
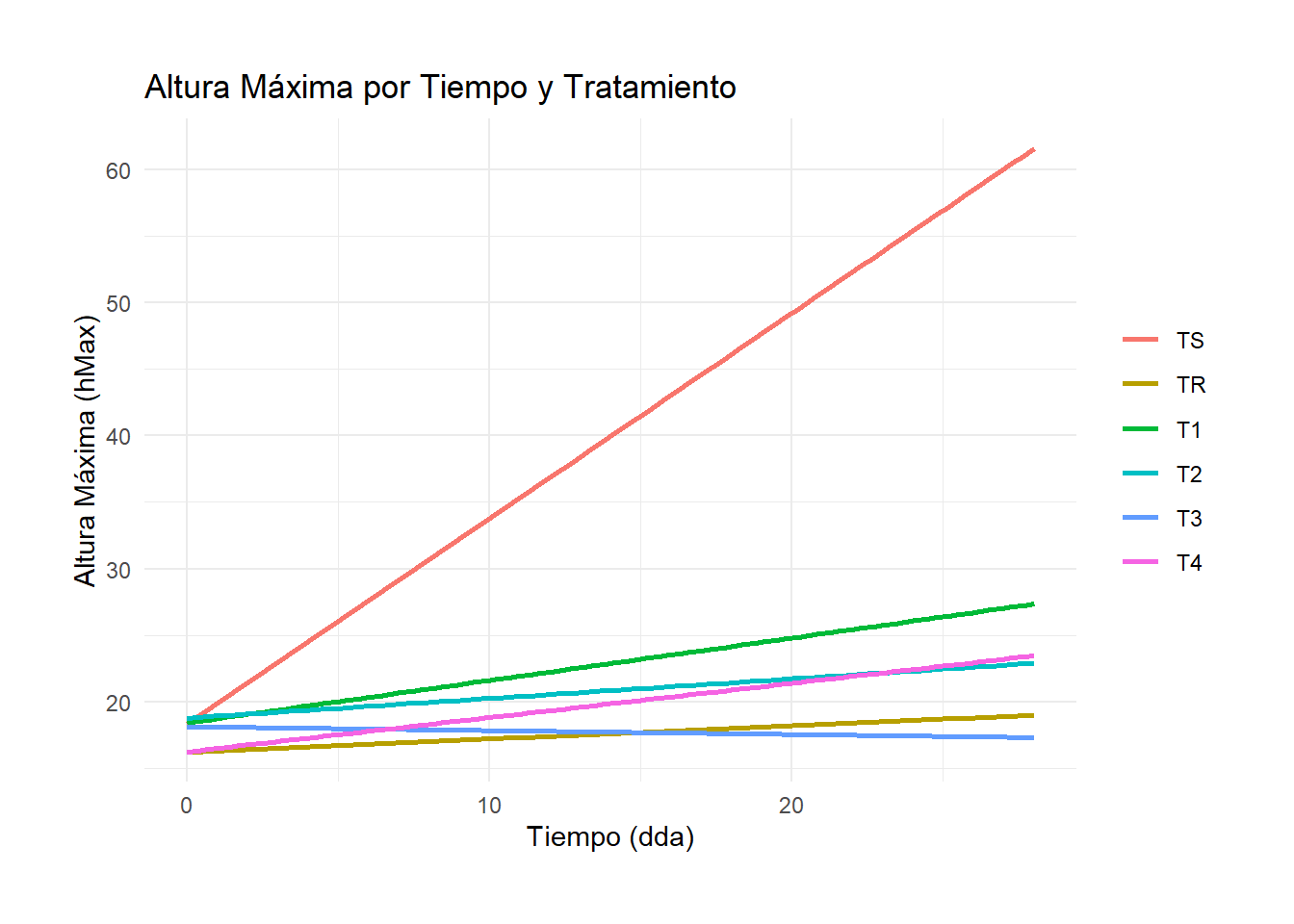
# Filtrar las columnas relevantes para hMaxdf_filtered_hmax <- df[, c("Tratamiento", "hMax0dda", "hMax14dda", "hMax19dda", "hMax28dda")]# Renombrar las columnas para que tengan las etiquetas deseadascolnames(df_filtered_hmax) <-c("Tratamiento", "0 dda", "14 dda", "19 dda", "28 dda")# Convertir el dataframe a formato largodf_melted_hmax <-melt(df_filtered_hmax, id.vars ="Tratamiento", variable.name ="Tiempo", value.name ="hMax")# Convertir la columna Tiempo a numérica para la regresióndf_melted_hmax$Tiempo <-as.numeric(gsub(" dda", "", df_melted_hmax$Tiempo))# Convertir Tratamiento a factor y especificar el nivel de referencia y el orden de los nivelesdf_melted_hmax$Tratamiento <-factor(df_melted_hmax$Tratamiento, levels =c("TS", "TR", "T1", "T2", "T3", "T4"))# Ajustar modelos lineales para cada tratamientomodels_hmax <-lm(hMax ~ Tiempo * Tratamiento, data = df_melted_hmax)summary(models_hmax)